Cet article fait partie de la série des articles sur la création d’une IA locale dans mon bureau : Créer une IA locale.
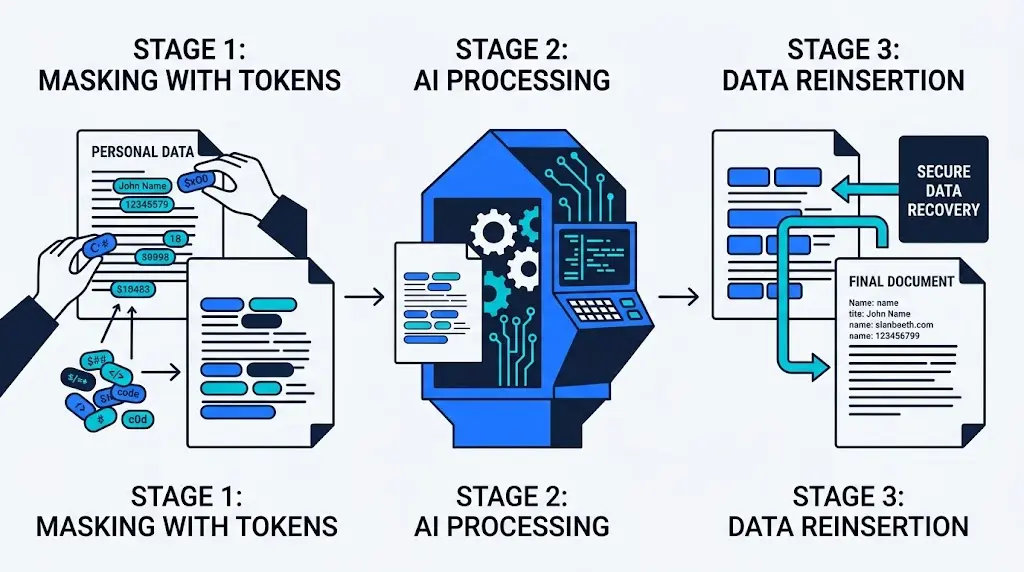
Anonymiser un document, c’est supprimer définitivement les données personnelles qu’il contient. Pseudonymiser, c’est différent : tu remplaces temporairement ces données par un identifiant neutre, tu traites le document sans jamais voir l’information sensible, puis tu réinjectes les vraies données à la fin. Voici comment tester ce principe chez toi, sur un PC modeste, avec des outils open source.
Le principe en 3 étapes
Détecter les données personnelles dans un texte et les remplacer par un jeton neutre (par exemple PERSONNE_1 à la place d’un prénom).
Traiter le texte anonymisé avec une intelligence artificielle, qui ne voit jamais l’identité réelle de la personne.
Réinjecter l’information réelle à la place du jeton dans le résultat final.
L’intérêt : le traitement (recherche, analyse, génération de contenu) se fait sans exposer l’identité de la personne concernée, ce qui limite les risques si le document venait à être mal utilisé ou transmis à un tiers.
Les outils utilisés
Presidio, un outil open source de Microsoft, pour détecter les données personnelles dans le texte (reconnaissance d’entités nommées).
spaCy, une bibliothèque de traitement du langage, utilisée par Presidio pour comprendre le texte en français.
Ollama avec le modèle qwen2.5:3b, pour le traitement IA local, sans aucune donnée envoyée sur internet.
Tout tourne en local sur un Mini PC Linux, sans connexion à un service externe.
Installer l’environnement
Le script tourne dans un environnement Python isolé (un venv), séparé du reste du système. Ça évite que les bibliothèques installées pour ce projet entrent en conflit avec d’autres outils déjà présents sur la machine.
Crée le dossier du projet et vérifie que le paquet nécessaire à la création d’un venv est installé :
mkdir -p ~/docker/pseudonymisation
cd ~/docker/pseudonymisation
dpkg -l | grep python3-venv
Si la commande ne retourne rien, installe le paquet (le numéro de version dépend de ta machine, la commande d’installation exacte apparaît dans le message d’erreur si tu tentes de créer le venv directement) :
sudo apt update
sudo apt upgrade
sudo reboot
Après le redémarrage, reconnecte-toi en SSH et installe le paquet indiqué par le message d’erreur, par exemple :
sudo apt install python3.12-venv
Crée ensuite le venv, sans sudo (une commande avec sudo donnerait les droits root aux fichiers créés, ce qui complique ensuite toute modification) :
cd ~/docker/pseudonymisation
python3 -m venv venv
source venv/bin/activate
La ligne de commande affiche maintenant (venv) au début, signe que l’environnement isolé est actif. Installe les bibliothèques nécessaires et le modèle de langue française :
Le modèle fr_core_news_sm est le plus léger disponible pour le français. Sur un PC peu puissant et pour un test avec des textes courts, il est peut-être suffisant. Un modèle plus complet (fr_core_news_md) existe si la détection s’avère insuffisante.
Enregistre la liste des bibliothèques installées, pour pouvoir tout réinstaller à l’identique en cas de besoin :
pip freeze > requirements.txt
Vérifier que la détection fonctionne
Avant de construire le script complet, un test simple permet de vérifier que Presidio détecte bien un prénom dans une phrase.
Crée le fichier test_detection.py :
from presidio_analyzer import AnalyzerEngine
from presidio_analyzer.nlp_engine import NlpEngineProvider
configuration = {
"nlp_engine_name": "spacy",
"models": [{"lang_code": "fr", "model_name": "fr_core_news_sm"}]
}
provider = NlpEngineProvider(nlp_configuration=configuration)
nlp_engine = provider.create_engine()
analyzer = AnalyzerEngine(nlp_engine=nlp_engine, supported_languages=["fr"])
texte_origine = "Bonjour, je m'appelle Pierre Durand et j'habite à Paris."
resultats = analyzer.analyze(text=texte_origine, language="fr")
for res in resultats:
print(f"Trouvé: {texte_origine[res.start:res.end]} -> Catégorie: {res.entity_type}")
Lance-le :
python test_detection.py
Résultat obtenu :
Trouvé: Pierre Durand -> Catégorie: PERSON
Trouvé: Paris -> Catégorie: LOCATION
La détection fonctionne, on peut construire le script complet.
Créer des documents de test
Pour tester le workflow, j’ai créé 5 courts textes fictifs, chacun avec un prénom, un âge et un animal préféré, rédigés comme des présentations naturelles plutôt que des formulaires. Crée un dossier documents/ et un fichier par personne :
mkdir -p ~/docker/pseudonymisation/documents
cat > ~/docker/pseudonymisation/documents/personne1.txt << 'EOF'
Bonjour, je m'appelle Léa et j'ai 34 ans. Je travaille dans une pépinière depuis quelques années. Si je devais choisir un animal préféré, ce serait sans hésiter l'axolotl, je trouve sa capacité à régénérer ses membres absolument fascinante.
EOF
cat > ~/docker/pseudonymisation/documents/personne2.txt << 'EOF'
Je me présente, je suis Thomas, j'ai 52 ans et je vis à la campagne. Mon animal préféré est le fennec, ses grandes oreilles et son adaptation au désert m'ont toujours impressionné depuis un documentaire vu il y a longtemps.
EOF
cat > ~/docker/pseudonymisation/documents/personne3.txt << 'EOF'
Salut, moi c'est Camille, 27 ans. J'adore les animaux un peu décalés, et mon préféré reste le quokka, ce petit marsupial australien qui semble toujours sourire sur les photos.
EOF
cat > ~/docker/pseudonymisation/documents/personne4.txt << 'EOF'
Je m'appelle Julien et j'ai 45 ans. Passionné de nature depuis l'enfance, mon animal préféré est le pangolin, une créature discrète et méconnue que je trouve pourtant étonnante avec ses écailles.
EOF
cat > ~/docker/pseudonymisation/documents/personne5.txt << 'EOF'
Bonjour, je suis Sophie, j'ai 61 ans et je suis récemment partie à la retraite. Mon animal préféré est l'okapi, cet étrange cousin de la girafe que j'ai découvert lors d'un voyage il y a quelques années.
EOF
Le script d’anonymisation
Ce script lit chaque fichier, détecte les entités présentes (pas seulement le prénom, pour observer aussi ce que Presidio détecte d’autre), les remplace par des jetons, et sauvegarde la correspondance dans un fichier JSON.
Crée anonymisation.py :
import os
import json
from presidio_analyzer import AnalyzerEngine
from presidio_analyzer.nlp_engine import NlpEngineProvider
DOSSIER_SOURCE = "documents"
DOSSIER_ANONYMISE = "documents_anonymises"
DOSSIER_RECONSTRUIT = "documents_reconstruits"
FICHIER_CORRESPONDANCE = "correspondance.json"
configuration = {
"nlp_engine_name": "spacy",
"models": [{"lang_code": "fr", "model_name": "fr_core_news_sm"}]
}
provider = NlpEngineProvider(nlp_configuration=configuration)
nlp_engine = provider.create_engine()
analyzer = AnalyzerEngine(nlp_engine=nlp_engine, supported_languages=["fr"])
os.makedirs(DOSSIER_ANONYMISE, exist_ok=True)
os.makedirs(DOSSIER_RECONSTRUIT, exist_ok=True)
correspondance_globale = {}
for nom_fichier in sorted(os.listdir(DOSSIER_SOURCE)):
if not nom_fichier.endswith(".txt"):
continue
chemin_source = os.path.join(DOSSIER_SOURCE, nom_fichier)
with open(chemin_source, "r", encoding="utf-8") as f:
texte = f.read()
resultats = analyzer.analyze(text=texte, language="fr")
resultats_tries = sorted(resultats, key=lambda r: r.start, reverse=True)
correspondance_fichier = {"prenom": None, "autres_elements_personnels": []}
texte_anonymise = texte
compteur_autres = 0
prenom_trouve = False
for res in resultats_tries:
valeur = texte[res.start:res.end]
if res.entity_type == "PERSON" and not prenom_trouve:
jeton = "PERSONNE_1"
correspondance_fichier["prenom"] = {"jeton": jeton, "valeur": valeur}
prenom_trouve = True
else:
compteur_autres += 1
jeton = f"AUTRE_{compteur_autres}"
correspondance_fichier["autres_elements_personnels"].append(
{"jeton": jeton, "valeur": valeur, "categorie": res.entity_type}
)
texte_anonymise = texte_anonymise[:res.start] + jeton + texte_anonymise[res.end:]
with open(os.path.join(DOSSIER_ANONYMISE, nom_fichier), "w", encoding="utf-8") as f:
f.write(texte_anonymise)
correspondance_globale[nom_fichier] = correspondance_fichier
texte_reconstruit = texte_anonymise
if correspondance_fichier["prenom"]:
texte_reconstruit = texte_reconstruit.replace(
correspondance_fichier["prenom"]["jeton"],
"[ " + correspondance_fichier["prenom"]["valeur"] + " ]"
)
if correspondance_fichier["autres_elements_personnels"]:
texte_reconstruit += "\n\nAutres elements personnels detectes :\n"
for item in correspondance_fichier["autres_elements_personnels"]:
texte_reconstruit += f"- {item['jeton']} : {item['valeur']} ({item['categorie']})\n"
with open(os.path.join(DOSSIER_RECONSTRUIT, nom_fichier), "w", encoding="utf-8") as f:
f.write(texte_reconstruit)
with open(FICHIER_CORRESPONDANCE, "w", encoding="utf-8") as f:
json.dump(correspondance_globale, f, ensure_ascii=False, indent=2)
print("Termine. Verifie documents_anonymises/, documents_reconstruits/ et correspondance.json")
Lance le script :
python anonymisation.py
Le dossier documents_reconstruits/ sert de test intermédiaire : il réinjecte immédiatement le prénom entre crochets ([ Léa ]) pour vérifier visuellement que le mécanisme fonctionne, avant même d’ajouter le traitement IA.
Sur les 5 documents testés, la détection a globalement bien fonctionné, avec deux limites observées :
sur personne1.txt, Presidio n’a détecté aucune entité, y compris le prénom Léa pourtant présent en clair. Le modèle léger fr_core_news_sm peut manquer certains prénoms.
sur personne3.txt, le mot « Salut » a été classé comme un lieu (LOCATION), un faux positif.
Ces limites sont attendues avec un modèle allégé et font partie de ce qu’on cherche à observer dans ce test.
Le traitement par IA
Le texte anonymisé est envoyé à qwen2.5:3b via Ollama, avec une consigne qui demande à la fois l’animal préféré et un signalement de toute donnée personnelle restante dans le texte, une façon de vérifier si l’IA repère les éventuels oublis de l’étape précédente.
Un test sur un seul fichier permet de vérifier le format de réponse avant de généraliser :
import requests
with open("documents_anonymises/personne2.txt", "r", encoding="utf-8") as f:
texte_anonymise = f.read()
prompt = f"""Voici un texte. Reponds uniquement avec ce format exact, sans phrase supplementaire :
Animal prefere : [ton animal trouve]
Attention - donnees personnelles : [liste les elements qui sont des donnees personnelles, ou ecris "aucun"]
Texte : {texte_anonymise}"""
reponse = requests.post(
"http://localhost:11434/api/generate",
json={"model": "qwen2.5:3b", "prompt": prompt, "stream": False}
)
print(reponse.json()["response"])
Une fois le format validé, le script complet traite les 5 documents :
import os
import json
import requests
DOSSIER_ANONYMISE = "documents_anonymises"
FICHIER_RESULTATS = "resultats_ia.json"
resultats = {}
for nom_fichier in sorted(os.listdir(DOSSIER_ANONYMISE)):
if not nom_fichier.endswith(".txt"):
continue
chemin = os.path.join(DOSSIER_ANONYMISE, nom_fichier)
with open(chemin, "r", encoding="utf-8") as f:
texte_anonymise = f.read()
prompt = f"""Voici un texte. Reponds uniquement avec ce format exact, sans phrase supplementaire :
Animal prefere : [ton animal trouve]
Attention - donnees personnelles : [liste les elements qui sont des donnees personnelles, ou ecris "aucun"]
Texte : {texte_anonymise}"""
reponse = requests.post(
"http://localhost:11434/api/generate",
json={"model": "qwen2.5:3b", "prompt": prompt, "stream": False}
)
resultats[nom_fichier] = reponse.json()["response"]
print(f"{nom_fichier} traite.")
with open(FICHIER_RESULTATS, "w", encoding="utf-8") as f:
json.dump(resultats, f, ensure_ascii=False, indent=2)
print("Termine. Verifie resultats_ia.json")
Sur plusieurs exécutions successives de ce script, un même document (personne5.txt) a systématiquement échoué à respecter le format demandé : au lieu de répondre selon la consigne, le modèle a recopié le texte source. Un autre document a échoué une fois sur trois essais, avant de fonctionner correctement. Ce comportement n’est pas lié au prompt (qui fonctionne pour la majorité des textes), plutôt à une limite connue des petits modèles sur le respect strict d’un format de sortie.
La réinjection finale
Le dernier script combine le prénom réel, l’animal trouvé par l’IA et les éventuelles autres données personnelles détectées, pour produire un document final par personne :
import os
import json
FICHIER_CORRESPONDANCE = "correspondance.json"
FICHIER_RESULTATS_IA = "resultats_ia.json"
DOSSIER_FINAL = "documents_finaux"
with open(FICHIER_CORRESPONDANCE, "r", encoding="utf-8") as f:
correspondance = json.load(f)
with open(FICHIER_RESULTATS_IA, "r", encoding="utf-8") as f:
resultats_ia = json.load(f)
os.makedirs(DOSSIER_FINAL, exist_ok=True)
for nom_fichier, corr in correspondance.items():
prenom = corr["prenom"]["valeur"] if corr["prenom"] else "PRENOM_NON_DETECTE"
reponse_ia = resultats_ia.get(nom_fichier, "")
animal = "non determine (echec du modele IA)"
for ligne in reponse_ia.splitlines():
if ligne.strip().lower().startswith("animal prefere"):
animal = ligne.split(":", 1)[1].strip()
break
contenu_final = f"Prenom : {prenom}\n"
contenu_final += f"Animal prefere : {animal}\n"
if corr["autres_elements_personnels"]:
contenu_final += "\nAutres elements personnels detectes :\n"
for item in corr["autres_elements_personnels"]:
contenu_final += f"- {item['jeton']} : {item['valeur']} ({item['categorie']})\n"
nom_sortie = nom_fichier.replace(".txt", "_final.txt")
with open(os.path.join(DOSSIER_FINAL, nom_sortie), "w", encoding="utf-8") as f:
f.write(contenu_final)
print("Termine. Verifie le dossier documents_finaux/")
Résultat obtenu sur les 5 documents :
Prenom : PRENOM_NON_DETECTE
Animal prefere : axolotl
Prenom : Thomas
Animal prefere : fennec
Prenom : Camille
Animal prefere : Quokka
Autres elements personnels detectes :
- AUTRE_1 : Salut (LOCATION)
Prenom : Julien
Animal prefere : pangolin
Prenom : Sophie
Animal prefere : non determine (echec du modele IA)
Chaque cas d’échec est signalé explicitement dans le document final, plutôt que masqué ou laissé vide, ce qui permet de voir immédiatement où le workflow a besoin d’être amélioré.
Ce qu’on a appris
Un PC ancien de bureautique suffit. Aucune lenteur notable, y compris pendant les 5 appels au modèle IA.
Le modèle spaCy léger a ses limites. Un prénom sur cinq n’a pas été détecté, et un faux positif est apparu sur un autre texte. Un modèle plus complet (fr_core_news_md) mériterait un test comparatif avant un usage réel.
Le petit modèle IA est inconstant sur le format. Un même texte peut réussir ou échouer à respecter la consigne selon l’essai. Une piste pour réduire cette variabilité, non testée ici : fixer le paramètre temperature à 0 dans la requête envoyée à Ollama.
Le principe fonctionne malgré ces limites. Le workflow complet, de la détection à la réinjection, tourne de bout en bout sans erreur bloquante, avec une gestion propre des cas d’échec.
Des cas d’usage possibles en entreprise
Ce principe dépasse largement le simple test avec des animaux préférés. Quelques exemples concrets :
Formulaires de contact ou de prospection : un prospect décrit son besoin, le texte est anonymisé avant d’être traité par une IA qui propose une base de réponse ou de devis, puis l’identité est réinjectée à la fin.
Formation : traiter des retours d’expérience ou des évaluations sans exposer l’identité des participants pendant l’analyse.
Plus largement, tout traitement IA sur des documents contenant des données sensibles, où l’on veut garder un contrôle strict sur qui voit quoi et à quel moment.
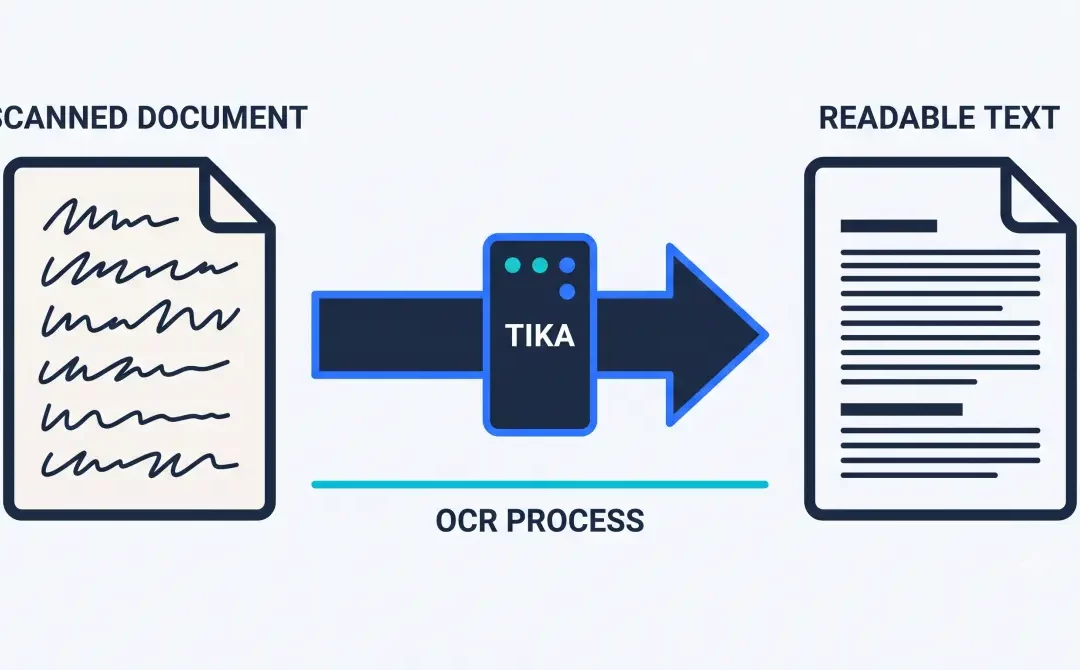
Open WebUI ne sait pas lire un PDF scanné : il faut une couche d’OCR. Tika, un service Apache open source, comble ce manque. Voici comment l’installer, le piège à éviter, et ce que ça change vraiment sur un Mini PC.
Cet article fait partie de deux séries :
la série des articles sur Linux et des logiciels installés en containers Docker : projets Ubuntu
la série des articles sur la création d’une IA locale dans mon bureau : Créer une IA locale
Pourquoi Tika
Si tu as suivi l’article sur le RAG dans Open WebUI, tu as déjà l’embedding configuré avec nomic-embed-text, et tu sais que les modèles texte uniquement comme qwen2.5:3b ne lisent que le texte extrait d’un PDF, jamais une image.
Le problème, c’est que rien ne distingue à l’œil un PDF texte natif d’un PDF scanné : seul le contenu diffère. Si tu déposes un PDF scanné sans précaution, Open WebUI l’indexe sans erreur visible, mais le document reste vide de tout texte utilisable. Le modèle répond alors qu’il ne trouve pas l’information, même si elle est sous ses yeux.
Tika résout ce problème : c’est un serveur qui extrait le texte de n’importe quel format de document, PDF compris, et qui sait appliquer une reconnaissance optique de caractères (OCR) quand le PDF est une image plutôt que du texte.
Étape 1 – Installer Tika via Portainer
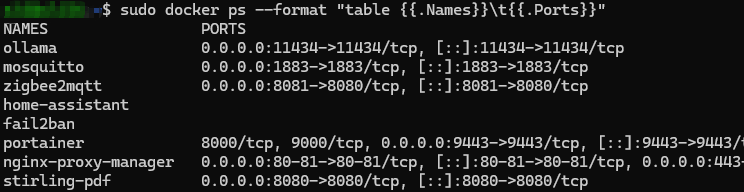
Avant d’installer un nouveau container, vérifie les ports déjà utilisés :
Tika ne nécessite pas de volume : il traite les fichiers à la volée, sans rien conserver entre les requêtes. Si tu veux un jour personnaliser son comportement (désactiver l’OCR, ajuster sa résolution), cela se fait via un fichier de configuration séparé, mais ce n’est pas nécessaire pour un usage standard.
Crée quand même un répertoire dédié, pour garder une trace du paramétrage en cas de réinstallation sur une autre machine :
Le piège à éviter : l’image apache/tika existe en deux versions. Le tag latest correspond à une version minimale, sans aucune capacité d’OCR. Pour que Tika sache lire un PDF scanné, il faut impérativement le tag latest-full, qui inclut Tesseract OCR. Avec le tag latest seul, l’installation semble fonctionner (le container démarre, le port répond), mais l’extraction d’un PDF image renvoie systématiquement un résultat vide, sans message d’erreur explicite.
Dans Portainer : Stacks > Add stack, nomme-le tika, colle le contenu ci-dessus dans l’éditeur web, puis déploie.
Si le texte du document s’affiche dans le terminal, l’OCR fonctionne. Une sortie vide signale que l’image utilisée n’est pas la version -full.
Étape 2 – Connecter Tika à Open WebUI
Connecte-toi à Open WebUI avec un compte administrateur, puis va dans Panneau d’administration > Réglages > Documents.
Dans Moteur d’extraction de contenu, sélectionne Tika, puis renseigne l’adresse du serveur :
http://tika:9998
Le nom tika correspond au nom du container, résolu automatiquement puisque Tika et Open WebUI partagent le même réseau Docker (ollama_default). Enregistre.
Je n’ai pas testé ce qui se passe pour des documents déjà indexés avant ce changement de moteur : il est possible qu’une réindexation soit nécessaire pour qu’ils bénéficient de l’OCR rétroactivement. Si tu pars d’une base de connaissances neuve, la question ne se pose pas.
Étape 3 – Tester avec un vrai PDF scanné
Pour être certain qu’un PDF est une image et non du texte, essaie de sélectionner du texte avec la souris dans une visionneuse PDF : si rien ne se sélectionne, c’est un scan.
Test en base de connaissances. Dans Espace de travail > Connaissances, ouvre une base existante (ou crée-en une), et dépose le PDF scanné. L’indexation se déroule sans erreur visible. Pose ensuite une question dont la réponse se trouve uniquement dans ce document, à l’agent associé à la base. La réponse est correcte et cite le document.
Test en pièce jointe directe. Dans une conversation normale, joins le même PDF directement au message, sans passer par une base de connaissances. La réponse arrive, correcte également, mais avec un temps de traitement nettement plus long.
Les deux scénarios fonctionnent : l’objectif principal (PDF scanné joint directement dans le chat) est atteint, tout comme le repli (PDF scanné en base de connaissances).
Le verdict : ça marche, mais c’est lent
Sur un Mini PC (Intel i5, 16 Go de RAM) qui fait déjà tourner Home Assistant, Mosquitto, Zigbee2MQTT, Ollama et Open WebUI, l’OCR via Tika consomme des ressources que la machine n’a pas en réserve. Le résultat est juste, mais l’attente se fait sentir, surtout en pièce jointe directe dans le chat.
Ce n’est pas une limite de Tika : l’OCR est par nature gourmand en calcul, quel que soit l’outil utilisé. Sur un matériel plus généreux, ou avec un GPU dédié, le temps de traitement serait nettement réduit.
Dans mon cas, je préfère donc réserver Tika à un usage ponctuel (l’indexation d’un PDF scanné dans une base de connaissances, qui ne se fait qu’une fois), plutôt qu’à un usage répété en pièce jointe directe dans une conversation. Pour les PDF que je sais scannés, je passe en amont par un OCR dédié avec Stirling PDF, déjà installé sur le même Mini PC selon la procédure décrite dans Installer et régler Stirling PDF via Docker. Le PDF ressort avec une couche de texte intégrée, et Open WebUI le traite alors comme un PDF texte natif classique, sans solliciter Tika.
Pour aller plus loin
Cet article fait partie d’une série sur l’IA locale : Créer une IA locale et l’installation de logiciels en containers Docker sous Ubuntu : projets Ubuntu
Ollama et Open WebUI installés, modèles téléchargés – le chat fonctionne. Mais si tu veux interroger tes propres documents sans les envoyer sur un serveur externe, il faut aller un cran plus loin : configurer le RAG. Cet article fait partie de deux séries :
la série des articles sur Linux et des logiciels installés en containers Docker : projets Ubuntu
La série des articles sur la création d’une IA locale dans mon bureau : Créer une IA locale
C’est quoi le RAG ?
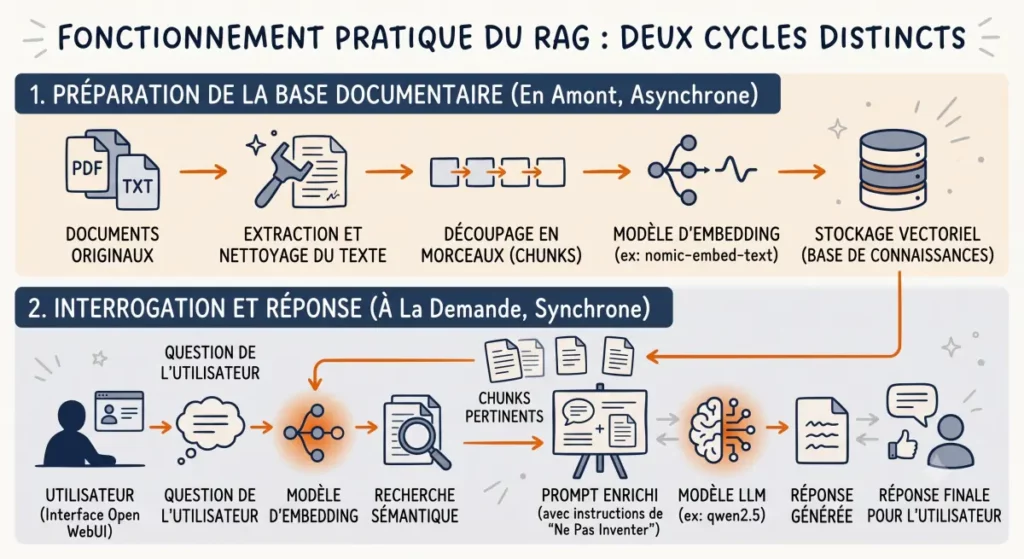
RAG est l’acronyme de « Retrieval-Augmented Generation » – en français, génération augmentée par récupération. L’idée est simple : plutôt que de demander au modèle de répondre uniquement à partir de ce qu’il a appris pendant son entraînement, on lui fournit des passages extraits de tes propres documents. Le modèle s’appuie sur ces passages pour construire sa réponse.
En pratique, ça change tout : tu peux créer un assistant qui connaît ta documentation interne, tes notes, tes rapports – et qui répond en citant ses sources. Et si c’est fait dans un système local, rien ne sort vers l’extérieur.
Le rôle de l’embedding
Pour que le RAG fonctionne, le système doit être capable de trouver rapidement les passages pertinents dans tes documents avant de les transmettre au modèle. C’est le rôle de l’embedding – qu’on pourrait traduire par vectorisation sémantique, même si ce terme n’est pas d’usage courant.
Un modèle d’embedding lit chaque paragraphe de tes documents et le convertit en une liste de coordonnées mathématiques – un vecteur. Deux paragraphes qui parlent du même sujet auront des coordonnées proches, même s’ils n’utilisent pas les mêmes mots. Quand tu poses une question, ta question est convertie de la même façon, et le système trouve en quelques millisecondes les paragraphes les plus proches.
Le LLM ne reçoit alors que ces quelques paragraphes pertinents – pas l’intégralité du document. Sur un CPU sans carte graphique dédiée, c’est ce qui rend le système utilisable : le modèle n’a que quelques lignes à lire pour formuler sa réponse.
Les modèles testés dans cet article : qwen2.5:3b comme LLM, nomic-embed-text comme modèle d’embedding
Étape 1 – Télécharger le modèle d’embedding
nomic-embed-text est un modèle léger (~270 Mo), rapide sur CPU, avec une fenêtre de contexte de 8192 tokens – ce qui permet de découper les documents en morceaux suffisamment grands pour conserver le sens.
nomic-embed-text doit apparaître dans la liste aux côtés de tes modèles LLM.
Étape 2 – Configurer l’embedding dans Open WebUI
Dans Open WebUI, connecte-toi avec ton compte administrateur, puis va dans Panneau d’administration > Réglages > Documents.
Dans la section Embedding :
Moteur de modèle d’embedding : sélectionne Ollama
Modèle d’embedding : saisis nomic-embed-text
Clique sur Enregistrer.
Open WebUI délègue désormais toute la vectorisation à Ollama. Les deux modèles – LLM et embedding – tournent sur le même moteur, sans duplication de ressources.
Étape 3 – Créer une base de connaissances
Une base de connaissances est un ensemble de documents indexés sur un thème donné. C’est l’équivalent local d’un Projet Claude ou d’un Gem Gemini – sans que rien ne sorte de ta machine.
Dans Open WebUI, va dans Espace de travail > Connaissances, puis crée une nouvelle base avec un nom explicite (par exemple « Réglementation formation » ou « Documentation projet X »).
Glisse-dépose tes fichiers PDF ou TXT dans la zone dédiée. Le CPU va s’activer quelques secondes – c’est nomic-embed-text qui indexe et vectorise les documents en arrière-plan. Une fois l’indexation terminée, la base est prête.
Quelques points à garder en tête :
Les modèles texte uniquement (qwen2.5:3b, llama3.1, mistral) ne peuvent pas traiter des images – seul le texte extrait des PDF est utilisable
Pour les très longs documents (plus de 50-100 pages), laisse le CPU terminer l’indexation avant d’en ajouter d’autres
Étape 4 – Créer un agent associé à la base
La base de connaissances seule ne fait rien – il faut lui associer un agent, c’est-à-dire un modèle configuré avec un comportement précis.
Dans Espace de travail > Modèles, clique sur Créer un modèle, puis :
Donne-lui un nom explicite (par exemple « Assistant formation »)
Modèle de base : sélectionne qwen2.5:3b
Dans la section Connaissances, associe la base créée à l’étape précédente
Rédige un system prompt
Le system prompt est crucial. Sans instruction claire, le modèle complète avec ses connaissances générales plutôt que de s’appuyer sur tes documents. Un exemple efficace :
« Tu es l’assistant de [ton rôle]. Tu réponds uniquement à partir des documents fournis dans ta base de connaissances. Si une information n’y figure pas, dis-le clairement sans inventer. Ne complète jamais avec tes connaissances générales. »
Sauvegarde. L’agent est prêt.
Ce que ça fait vraiment
Les tests sur cette configuration (Mini PC Ubuntu, Intel i5, 16 Go de RAM) donnent des résultats concluants sur des documents de quelques pages à une vingtaine de pages. Le modèle cite ses sources, répond aux questions dans le périmètre des documents, et indique clairement quand une information est absente.
Quelques limites à connaître :
Documents texte uniquement. Les modèles testés ici (qwen2.5:3b et les autres) ne traitent pas les images. Envoyer une image depuis Open WebUI produit une erreur. Seul le texte extrait des PDF est utilisable par le RAG.
Les PDF scannés nécessitent une étape supplémentaire. Le moteur d’extraction par défaut d’Open WebUI ne sait pas lire un PDF image (un scan sans couche texte). Si tu essaies d’en déposer un dans une base de connaissances, tu obtiendras une erreur silencieuse ou un document vide. La solution est d’ajouter Tika – un service Apache open source – comme moteur d’extraction. Tika s’installe en container Docker séparé et se connecte à Open WebUI via le réseau Docker. Ce point fait l’objet d’un article à venir dans cette série.
Le system prompt fait la différence. Sans instruction explicite de rester dans les sources, le modèle complète avec ses connaissances générales – les réponses paraissent correctes mais ne s’appuient pas sur tes documents. L’instruction « réponds uniquement à partir des documents fournis » change significativement le comportement.
Les réponses ne sont pas déterministes. Le même modèle, la même question, des sessions différentes peuvent produire des réponses légèrement différentes. C’est une caractéristique fondamentale des LLM, pas un dysfonctionnement – et une bonne raison de tester systématiquement après chaque modification de configuration.
Pour aller plus loin
Cet article fait partie d’une série sur l’IA locale : Créer une IA locale et l’installation de logiciels en containers Docker sous ubuntu : Créer une IA locale
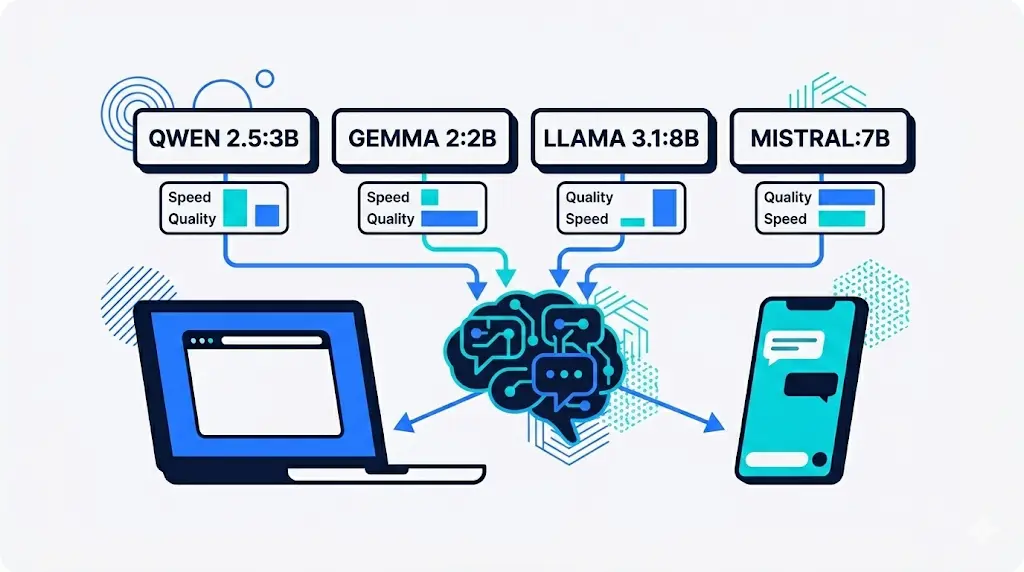
Ollama et Open web UI installés, modèles téléchargés – reste à savoir lequel utiliser au quotidien. Un prompt unique soumis aux 4 modèles permet de les départager rapidement sur ce qui compte : logique, maîtrise du français, et comportement de la machine.
La configuration de test
Mini PC sous Ubuntu, processeur Intel i5, 16 Go de RAM
Le même prompt a été soumis à chacun des 4 modèles, sans modification :
« Résous ce problème de logique étape par étape : Trois personnes (Alice, Bob et Charlie) ont chacune une couleur de pull différente (Bleu, Rouge, Vert). Alice dit qu’elle ne porte pas de bleu. Charlie porte un pull vert. Quelle est la couleur du pull de Bob ? Ensuite, traduis cette expression anglaise de manière naturelle en français : ‘It is raining cats and dogs’. Enfin, écris une seule phrase poétique sur la pluie. »
Ce prompt évalue quatre critères en une seule passe :
Logique : résoudre l’énigme par déduction (solution attendue : Bob = Bleu)
Traduction idiomatique : éviter la traduction littérale, trouver l’équivalent naturel en français
Créativité : qualité et fluidité de la phrase poétique
Comportement machine : vitesse d’affichage, charge CPU et RAM observées via htop
Conditions du test : avant chaque modèle, vérification qu’aucun autre modèle n’est chargé en RAM (sudo docker exec ollama ollama ps), et arrêt forcé si nécessaire (sudo docker exec ollama ollama stop <nom_du_modele>). Le chronométrage est fait à la main, du moment où le prompt est envoyé jusqu’à la fin de l’affichage de la réponse. Les modèles sont testés du plus léger au plus lourd.
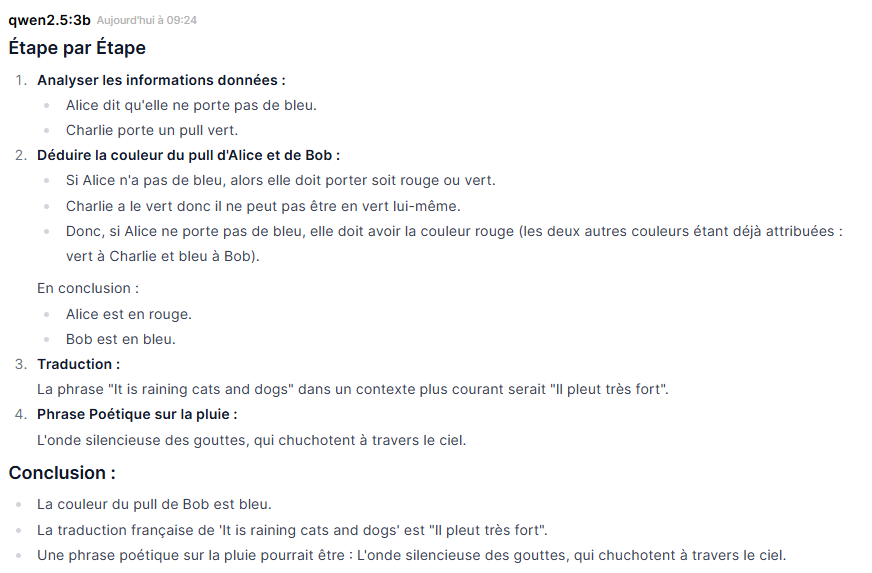
Traduction : correct mais en retrait. Il propose « Il pleut très fort » – ce qui est juste, mais banal. Lors d’une session précédente avec ce même modèle, il avait spontanément proposé quatre variantes idiomatiques (« Il pleut à torrents », « Il pleut à verse », « Il pleut comme jamais ») – une performance nettement meilleure. C’est un rappel utile : les LLM ne sont pas déterministes, la même question peut produire des réponses différentes d’une session à l’autre.
Poésie : correct, avec une image intéressante. « L’onde silencieuse des gouttes, qui chuchotent à travers le ciel. »
Machine : très bon comportement. Affichage quasi instantané, charge CPU modérée, RAM peu sollicitée. La machine reste disponible pendant et après le test.
gemma2:2b – Le petit modèle décevant
Durée : 30 secondes
Logique : faux. Il identifie correctement que Charlie porte le vert et qu’Alice ne porte pas le bleu, mais ne parvient pas à conclure correctement – il introduit même une couleur inexistante dans l’énoncé. C’est la limite des modèles à 2 milliards de paramètres : la surface cognitive est insuffisante pour enchaîner plusieurs étapes de déduction avec une négation.
Traduction : échec. Il traduit « It is raining cats and dogs » par « Il pleut des chats et des chiens » – traduction littérale, qui perd tout le sens de l’expression.
Poésie : il répond en anglais (« The sky weeps a soft, silver song »), ignorant la consigne en français.
Machine : comportement moyen. Plus lent que qwen2.5:3b malgré sa taille inférieure – l’architecture de Gemma est plus gourmande en ressources CPU relativement à sa taille.
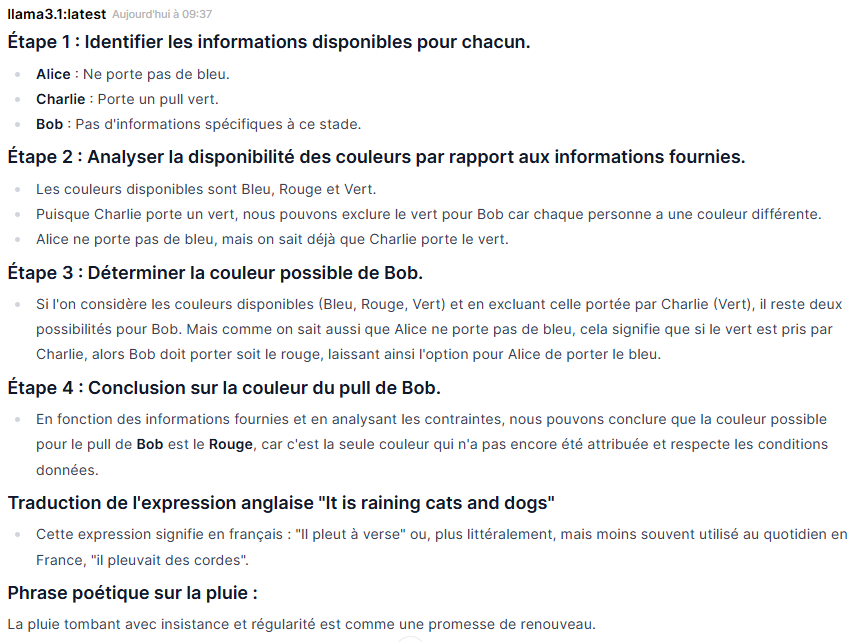
llama3.1 (8B) – Le raisonneur qui déraille
Durée : 2 minutes 17 secondes
Logique : faux. Le modèle développe un raisonnement structuré en plusieurs étapes, mais arrive à une conclusion erronée : il annonce Bob = Rouge, alors que la bonne réponse est Bob = Bleu. C’est d’autant plus surprenant que le raisonnement intermédiaire est correct – il identifie bien que Charlie = Vert et qu’Alice ne porte pas de bleu – mais la conclusion finale ne suit pas.
Traduction : parfait. « Il pleut des cordes » – sans hésitation, avec en complément « il pleut à verse ».
Poésie : correct. « La pluie tombant avec insistance et régularité est comme une promesse de renouveau. »
Machine : lourd. Affichage lent, charge CPU élevée sur les 8 coeurs, RAM fortement sollicitée. La machine reste saturée après le test et nécessite un arrêt forcé du modèle via sudo docker restart ollama pour revenir à la normale.
mistral (7B) – Les pieds dans le tapis
Durée : 1 minute 39 secondes
Logique : raisonnement contradictoire. Mistral part d’une bonne intuition mais son développement est incohérent : il affirme qu’Alice ne peut pas porter le vert alors que l’énoncé ne dit rien de tel, et conclut finalement Bob = Bleu – la bonne réponse – mais pour de mauvaises raisons. Un résultat juste obtenu par un chemin faux.
Traduction : mauvais, à deux titres. D’abord il donne la traduction littérale « Il pleut des chats et des chiens », puis tente de se rattraper en expliquant que « cela pleut beaucoup ». Cette formulation « cela pleut » est un calque direct de l’anglais « it’s raining » – un francophone écrit « il pleut », jamais « cela pleut ». Pour un modèle développé en France et réputé pour son français, c’est une déception.
Poésie : faute de grammaire. Mistral écrit « Les gouttes de pluie sont les diamants que tombent du ciel » – il aurait fallu écrire « qui tombent ». C’est la surprise du test : un modèle développé en France commet une erreur de syntaxe élémentaire sur sa langue maternelle. Cela illustre l’effet de la quantification – la compression du modèle pour réduire sa taille peut dégrader certaines compétences linguistiques, même sur la langue d’origine.
Machine : critique. Avec Home Assistant et les autres containers actifs en parallèle, la machine a atteint la limite de sa RAM physique et a commencé à utiliser le swap (espace disque utilisé comme mémoire de secours). Un arrêt forcé du container Ollama est nécessaire pour revenir à la normale.
Tableau récapitulatif
Critère
qwen2.5:3b
gemma2:2b
llama3.1 (8B)
mistral (7B)
Logique
Correct
Faux
Faux
Résultat juste, raisonnement faux
Traduction
Correct
Échec
Parfait
Mauvais
Poésie
Correct
Hors consigne
Correct
Faute de syntaxe
Durée
45 sec
31 sec
2 min 17
1 min 39
Impact machine
Léger
Moyen
Lourd
Critique
Ce que ce test apprend sur les LLM locaux
La taille ne fait pas tout. qwen2.5:3b (3 milliards de paramètres) surpasse gemma2:2b (2 milliards) sur tous les critères linguistiques, y compris la traduction en français, alors qu’il est plus grand. L’architecture et les données d’entraînement comptent autant que le nombre de paramètres.
Les LLM ne sont pas déterministes. Le même modèle, le même prompt, des résultats différents d’une session à l’autre. qwen a produit quatre variantes idiomatiques lors d’un premier passage, et une réponse banale lors du second. C’est une caractéristique fondamentale des LLM, pas un bug.
Les grands modèles ont un coût réel sur CPU. Llama 3.1 et Mistral sont utilisables, mais pas sur une machine déjà chargée par d’autres services. Sur un PC dédié uniquement à Ollama, le résultat serait différent.
Recommandation pour ma configuration
Au quotidien : qwen2.5:3b. Rapide, léger, correct en français, il ne sollicite pas la machine. C’est le modèle à utiliser en priorité sur une machine qui fait tourner d’autres services en parallèle.
Pour les tâches complexes : llama3.1 si la machine est disponible et si tu peux attendre – mais en gardant à l’esprit que ses performances en logique se sont révélées décevantes dans ce test.
À désinstaller : gemma2:2b. Ses performances en logique et en français sont insuffisantes, et il n’offre aucun avantage sur qwen2.5:3b.
À utiliser avec précaution : mistral. Son impact sur la RAM est trop important pour une machine partagée, et ses performances en français sont inférieures à ce qu’on pourrait attendre d’un modèle développé en France.
Nota
Ces modèles ne lisent pas les fichiers. Les 4 modèles testés sont des modèles texte uniquement. Envoyer un PDF ou une image depuis Open WebUI produit une erreur – le modèle ne sait pas traiter ce type d’entrée. Deux pistes pour y remédier : le RAG (Retrieval-Augmented Generation), qui permet d’interroger des documents en extrayant leur texte en amont, et les modèles multimodaux, capables de traiter des images directement. Ces deux sujets feront l’objet d’articles séparés.
Tu veux faire tourner un modèle d’IA en local, sans envoyer tes données sur un serveur externe ? Ollama gère les modèles, Open WebUI fournit l’interface – les deux s’installent en quelques minutes via Portainer.
Cette méthode fonctionne sur n’importe quel Ubuntu avec Docker et Portainer, que tu aies ou non d’autres containers en place. C’est pour faire fonctionner des modèles de langage qu’il peut être essentiel de réaliser cette installation sur un ordinateur un peu rapide, et pas trop occupé par d’autres activités. Les LLM consomment de l’espace disque pour leur stockage local (quelques giga octets par modèle) et de la mémoire vive lorsqu’ils sont utilisés (un ordinateur avec 8 Go de RAM minimum est recommandé, 16 Go si tu veux tester des modèles plus puissants).
Ce qu’on installe
Ollama est le moteur qui télécharge et fait tourner les modèles de langage (LLM). Il expose une API locale sur le port 11434. Il fonctionne en ligne de commande. Il ne stocke aucun historique de tes conversations.
Open WebUI est l’interface web qui se connecte à Ollama. Tu y accèdes depuis n’importe quel navigateur sur le même réseau local – PC Windows, tablette, Android. Open WebUI permet de disposer d’une interface de type « chat », pour « discuter » avec le LLM. Et Open WebUI assure le stockage de l’historique des conversations.
Les deux tournent en containers Docker séparés, avec leurs données dans /home/USER/docker/ pour être couverts par la sauvegarde automatique rclone (voir l’article sur la sauvegarde des containers).
Étape 1 – Installer Ollama
Créer le répertoire de config
bash
mkdir -p /home/USER/docker/ollama/config
Ce répertoire accueille tes fichiers de configuration personnalisés (Modelfiles). Les modèles eux-mêmes, qui peuvent peser plusieurs gigaoctets, sont stockés dans un volume Docker interne – ils ne sont pas sauvegardés, et se retéléchargent facilement si besoin.
Déployer la stack dans Portainer
Dans Portainer : Stacks > Add stack, donne le nom ollama, puis colle ce contenu dans le Web editor :
Remplace USER par ton nom d’utilisateur Linux, puis clique sur Deploy the stack.
Le réseau ollama_default est créé automatiquement par la première stack. Open WebUI s’y connecte pour joindre Ollama directement, sans passer par l’IP de la machine. C’est pour cette raison que les deux stacks doivent être déployées dans cet ordre.
Vérifier l’accès
Depuis n’importe quel navigateur sur ton réseau local :
http://IP_DU_PC_LINUX:3000
Tu dois voir l’interface Open WebUI. Le premier compte créé devient automatiquement administrateur – choisis un mot de passe solide.
Étape 3 – Télécharger un premier modèle
Dans Open WebUI, va dans Panneau d’administration > Réglages > Modèles, puis utilise l’option de téléchargement depuis Ollama pour récupérer un modèle.
Pour commencer, qwen2.5:3b est un bon choix : léger (environ 2,2 Go), rapide sur CPU, et d’excellente qualité en français.
Une fois téléchargé, ouvre une nouvelle conversation, sélectionne le modèle dans le menu déroulant en haut, et teste.
Ce qui est sauvegardé
Élément
Emplacement
Sauvegardé
Config et Modelfiles Ollama
/home/USER/docker/ollama/config/
Oui (rclone)
Données Open WebUI (historique, comptes)
/home/USER/docker/open-webui/data/
Oui (rclone)
Modèles LLM
Volume Docker interne
Non – à retélécharger
Les sauvegardes sont faites par rclone si vous avez fait la configuration indiquée plus haut (« ce qu’on installe »)


Commentaires récents