Ollama et Open web UI installés, modèles téléchargés – reste à savoir lequel utiliser au quotidien. Un prompt unique soumis aux 4 modèles permet de les départager rapidement sur ce qui compte : logique, maîtrise du français, et comportement de la machine.
La configuration de test
- Mini PC sous Ubuntu, processeur Intel i5, 16 Go de RAM
- Inférence CPU uniquement – pas de GPU dédié
- 4 modèles testés via Open WebUI connecté à Ollama. Voir le processus d’installation dans l’article Installer Ollama et Open WebUI sur Ubuntu avec Docker.
Les 4 modèles et leurs caractéristiques :
| Modèle | Taille | Profil |
|---|---|---|
| qwen2.5:3b | ~2,2 Go RAM | Petit modèle, développé par Alibaba |
| gemma2:2b | ~1,6 Go RAM | Très compact, développé par Google |
| llama3.1 (8B) | ~4,7 Go RAM | Modèle de référence de Meta |
| mistral (7B) | ~4,1 Go RAM | Développé en France par Mistral AI |
Le protocole : un seul prompt, quatre critères
Le même prompt a été soumis à chacun des 4 modèles, sans modification :
« Résous ce problème de logique étape par étape : Trois personnes (Alice, Bob et Charlie) ont chacune une couleur de pull différente (Bleu, Rouge, Vert). Alice dit qu’elle ne porte pas de bleu. Charlie porte un pull vert. Quelle est la couleur du pull de Bob ? Ensuite, traduis cette expression anglaise de manière naturelle en français : ‘It is raining cats and dogs’. Enfin, écris une seule phrase poétique sur la pluie. »
Ce prompt évalue quatre critères en une seule passe :
- Logique : résoudre l’énigme par déduction (solution attendue : Bob = Bleu)
- Traduction idiomatique : éviter la traduction littérale, trouver l’équivalent naturel en français
- Créativité : qualité et fluidité de la phrase poétique
- Comportement machine : vitesse d’affichage, charge CPU et RAM observées via htop
Conditions du test : avant chaque modèle, vérification qu’aucun autre modèle n’est chargé en RAM (sudo docker exec ollama ollama ps), et arrêt forcé si nécessaire (sudo docker exec ollama ollama stop <nom_du_modele>). Le chronométrage est fait à la main, du moment où le prompt est envoyé jusqu’à la fin de l’affichage de la réponse. Les modèles sont testés du plus léger au plus lourd.
Résultats modèle par modèle
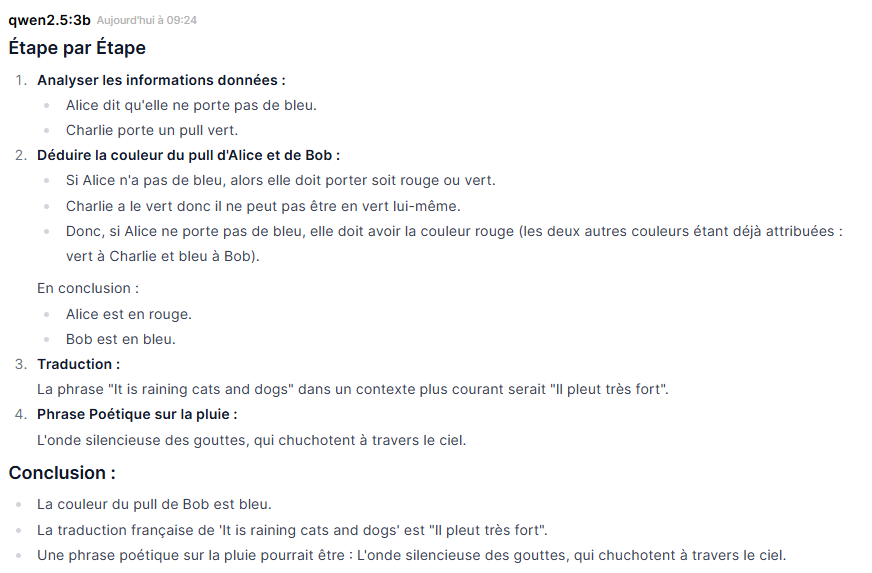
qwen2.5:3b – L’outsider agile
Durée : 44 secondes
Logique : correct. Raisonnement concis, conclusion juste (Bob = Bleu).
Traduction : correct mais en retrait. Il propose « Il pleut très fort » – ce qui est juste, mais banal. Lors d’une session précédente avec ce même modèle, il avait spontanément proposé quatre variantes idiomatiques (« Il pleut à torrents », « Il pleut à verse », « Il pleut comme jamais ») – une performance nettement meilleure. C’est un rappel utile : les LLM ne sont pas déterministes, la même question peut produire des réponses différentes d’une session à l’autre.
Poésie : correct, avec une image intéressante. « L’onde silencieuse des gouttes, qui chuchotent à travers le ciel. »
Machine : très bon comportement. Affichage quasi instantané, charge CPU modérée, RAM peu sollicitée. La machine reste disponible pendant et après le test.
gemma2:2b – Le petit modèle décevant
Durée : 30 secondes
Logique : faux. Il identifie correctement que Charlie porte le vert et qu’Alice ne porte pas le bleu, mais ne parvient pas à conclure correctement – il introduit même une couleur inexistante dans l’énoncé. C’est la limite des modèles à 2 milliards de paramètres : la surface cognitive est insuffisante pour enchaîner plusieurs étapes de déduction avec une négation.
Traduction : échec. Il traduit « It is raining cats and dogs » par « Il pleut des chats et des chiens » – traduction littérale, qui perd tout le sens de l’expression.
Poésie : il répond en anglais (« The sky weeps a soft, silver song »), ignorant la consigne en français.
Machine : comportement moyen. Plus lent que qwen2.5:3b malgré sa taille inférieure – l’architecture de Gemma est plus gourmande en ressources CPU relativement à sa taille.

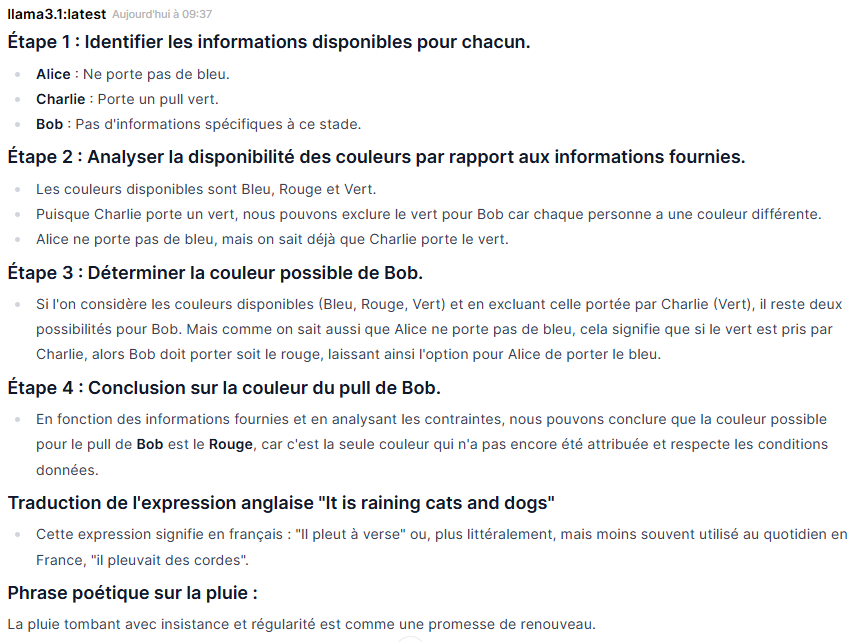
llama3.1 (8B) – Le raisonneur qui déraille
Durée : 2 minutes 17 secondes
Logique : faux. Le modèle développe un raisonnement structuré en plusieurs étapes, mais arrive à une conclusion erronée : il annonce Bob = Rouge, alors que la bonne réponse est Bob = Bleu. C’est d’autant plus surprenant que le raisonnement intermédiaire est correct – il identifie bien que Charlie = Vert et qu’Alice ne porte pas de bleu – mais la conclusion finale ne suit pas.
Traduction : parfait. « Il pleut des cordes » – sans hésitation, avec en complément « il pleut à verse ».
Poésie : correct. « La pluie tombant avec insistance et régularité est comme une promesse de renouveau. »
Machine : lourd. Affichage lent, charge CPU élevée sur les 8 coeurs, RAM fortement sollicitée. La machine reste saturée après le test et nécessite un arrêt forcé du modèle via sudo docker restart ollama pour revenir à la normale.
mistral (7B) – Les pieds dans le tapis
Durée : 1 minute 39 secondes
Logique : raisonnement contradictoire. Mistral part d’une bonne intuition mais son développement est incohérent : il affirme qu’Alice ne peut pas porter le vert alors que l’énoncé ne dit rien de tel, et conclut finalement Bob = Bleu – la bonne réponse – mais pour de mauvaises raisons. Un résultat juste obtenu par un chemin faux.
Traduction : mauvais, à deux titres. D’abord il donne la traduction littérale « Il pleut des chats et des chiens », puis tente de se rattraper en expliquant que « cela pleut beaucoup ». Cette formulation « cela pleut » est un calque direct de l’anglais « it’s raining » – un francophone écrit « il pleut », jamais « cela pleut ». Pour un modèle développé en France et réputé pour son français, c’est une déception.
Poésie : faute de grammaire. Mistral écrit « Les gouttes de pluie sont les diamants que tombent du ciel » – il aurait fallu écrire « qui tombent ». C’est la surprise du test : un modèle développé en France commet une erreur de syntaxe élémentaire sur sa langue maternelle. Cela illustre l’effet de la quantification – la compression du modèle pour réduire sa taille peut dégrader certaines compétences linguistiques, même sur la langue d’origine.
Machine : critique. Avec Home Assistant et les autres containers actifs en parallèle, la machine a atteint la limite de sa RAM physique et a commencé à utiliser le swap (espace disque utilisé comme mémoire de secours). Un arrêt forcé du container Ollama est nécessaire pour revenir à la normale.

Tableau récapitulatif
| Critère | qwen2.5:3b | gemma2:2b | llama3.1 (8B) | mistral (7B) |
|---|---|---|---|---|
| Logique | Correct | Faux | Faux | Résultat juste, raisonnement faux |
| Traduction | Correct | Échec | Parfait | Mauvais |
| Poésie | Correct | Hors consigne | Correct | Faute de syntaxe |
| Durée | 45 sec | 31 sec | 2 min 17 | 1 min 39 |
| Impact machine | Léger | Moyen | Lourd | Critique |
Ce que ce test apprend sur les LLM locaux
La taille ne fait pas tout. qwen2.5:3b (3 milliards de paramètres) surpasse gemma2:2b (2 milliards) sur tous les critères linguistiques, y compris la traduction en français, alors qu’il est plus grand. L’architecture et les données d’entraînement comptent autant que le nombre de paramètres.
Les LLM ne sont pas déterministes. Le même modèle, le même prompt, des résultats différents d’une session à l’autre. qwen a produit quatre variantes idiomatiques lors d’un premier passage, et une réponse banale lors du second. C’est une caractéristique fondamentale des LLM, pas un bug.
Les grands modèles ont un coût réel sur CPU. Llama 3.1 et Mistral sont utilisables, mais pas sur une machine déjà chargée par d’autres services. Sur un PC dédié uniquement à Ollama, le résultat serait différent.
Recommandation pour ma configuration
Au quotidien : qwen2.5:3b. Rapide, léger, correct en français, il ne sollicite pas la machine. C’est le modèle à utiliser en priorité sur une machine qui fait tourner d’autres services en parallèle.
Pour les tâches complexes : llama3.1 si la machine est disponible et si tu peux attendre – mais en gardant à l’esprit que ses performances en logique se sont révélées décevantes dans ce test.
À désinstaller : gemma2:2b. Ses performances en logique et en français sont insuffisantes, et il n’offre aucun avantage sur qwen2.5:3b.
À utiliser avec précaution : mistral. Son impact sur la RAM est trop important pour une machine partagée, et ses performances en français sont inférieures à ce qu’on pourrait attendre d’un modèle développé en France.
Nota
Ces modèles ne lisent pas les fichiers. Les 4 modèles testés sont des modèles texte uniquement. Envoyer un PDF ou une image depuis Open WebUI produit une erreur – le modèle ne sait pas traiter ce type d’entrée. Deux pistes pour y remédier : le RAG (Retrieval-Augmented Generation), qui permet d’interroger des documents en extrayant leur texte en amont, et les modèles multimodaux, capables de traiter des images directement. Ces deux sujets feront l’objet d’articles séparés.

Commentaires récents