Ollama et Open WebUI installés, modèles téléchargés – le chat fonctionne. Mais si tu veux interroger tes propres documents sans les envoyer sur un serveur externe, il faut aller un cran plus loin : configurer le RAG.
Cet article fait partie de deux séries :
- la série des articles sur Linux et des logiciels installés en containers Docker : projets Ubuntu
- La série des articles sur la création d’une IA locale dans mon bureau : Créer une IA locale
C’est quoi le RAG ?
RAG est l’acronyme de « Retrieval-Augmented Generation » – en français, génération augmentée par récupération. L’idée est simple : plutôt que de demander au modèle de répondre uniquement à partir de ce qu’il a appris pendant son entraînement, on lui fournit des passages extraits de tes propres documents. Le modèle s’appuie sur ces passages pour construire sa réponse.
En pratique, ça change tout : tu peux créer un assistant qui connaît ta documentation interne, tes notes, tes rapports – et qui répond en citant ses sources. Et si c’est fait dans un système local, rien ne sort vers l’extérieur.
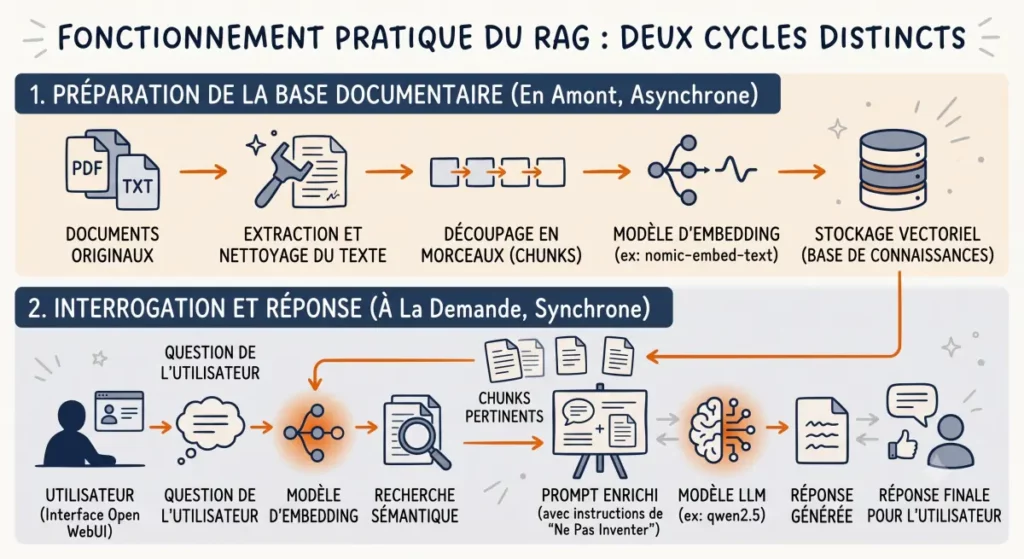
Le rôle de l’embedding
Pour que le RAG fonctionne, le système doit être capable de trouver rapidement les passages pertinents dans tes documents avant de les transmettre au modèle. C’est le rôle de l’embedding – qu’on pourrait traduire par vectorisation sémantique, même si ce terme n’est pas d’usage courant.
Un modèle d’embedding lit chaque paragraphe de tes documents et le convertit en une liste de coordonnées mathématiques – un vecteur. Deux paragraphes qui parlent du même sujet auront des coordonnées proches, même s’ils n’utilisent pas les mêmes mots. Quand tu poses une question, ta question est convertie de la même façon, et le système trouve en quelques millisecondes les paragraphes les plus proches.
Le LLM ne reçoit alors que ces quelques paragraphes pertinents – pas l’intégralité du document. Sur un CPU sans carte graphique dédiée, c’est ce qui rend le système utilisable : le modèle n’a que quelques lignes à lire pour formuler sa réponse.
Prérequis
- Ollama et Open WebUI installés et fonctionnels – voir Installer Ollama et Open WebUI sur Ubuntu avec Docker
- Un compte administrateur sur Open WebUI
- Les modèles testés dans cet article : qwen2.5:3b comme LLM, nomic-embed-text comme modèle d’embedding
Étape 1 – Télécharger le modèle d’embedding
nomic-embed-text est un modèle léger (~270 Mo), rapide sur CPU, avec une fenêtre de contexte de 8192 tokens – ce qui permet de découper les documents en morceaux suffisamment grands pour conserver le sens.
Dans un terminal sur le Mini PC Linux :
sudo docker exec ollama ollama pull nomic-embed-text
Vérifie qu’il est bien disponible :
sudo docker exec ollama ollama list
nomic-embed-text doit apparaître dans la liste aux côtés de tes modèles LLM.
Étape 2 – Configurer l’embedding dans Open WebUI
Dans Open WebUI, connecte-toi avec ton compte administrateur, puis va dans Panneau d’administration > Réglages > Documents.
Dans la section Embedding :
- Moteur de modèle d’embedding : sélectionne Ollama
- Modèle d’embedding : saisis
nomic-embed-text
Clique sur Enregistrer.
Open WebUI délègue désormais toute la vectorisation à Ollama. Les deux modèles – LLM et embedding – tournent sur le même moteur, sans duplication de ressources.
Étape 3 – Créer une base de connaissances
Une base de connaissances est un ensemble de documents indexés sur un thème donné. C’est l’équivalent local d’un Projet Claude ou d’un Gem Gemini – sans que rien ne sorte de ta machine.
Dans Open WebUI, va dans Espace de travail > Connaissances, puis crée une nouvelle base avec un nom explicite (par exemple « Réglementation formation » ou « Documentation projet X »).
Glisse-dépose tes fichiers PDF ou TXT dans la zone dédiée. Le CPU va s’activer quelques secondes – c’est nomic-embed-text qui indexe et vectorise les documents en arrière-plan. Une fois l’indexation terminée, la base est prête.
Quelques points à garder en tête :
- Les modèles texte uniquement (qwen2.5:3b, llama3.1, mistral) ne peuvent pas traiter des images – seul le texte extrait des PDF est utilisable
- Pour les très longs documents (plus de 50-100 pages), laisse le CPU terminer l’indexation avant d’en ajouter d’autres
Étape 4 – Créer un agent associé à la base
La base de connaissances seule ne fait rien – il faut lui associer un agent, c’est-à-dire un modèle configuré avec un comportement précis.
Dans Espace de travail > Modèles, clique sur Créer un modèle, puis :
- Donne-lui un nom explicite (par exemple « Assistant formation »)
- Modèle de base : sélectionne
qwen2.5:3b - Dans la section Connaissances, associe la base créée à l’étape précédente
- Rédige un system prompt
Le system prompt est crucial. Sans instruction claire, le modèle complète avec ses connaissances générales plutôt que de s’appuyer sur tes documents. Un exemple efficace :
« Tu es l’assistant de [ton rôle]. Tu réponds uniquement à partir des documents fournis dans ta base de connaissances. Si une information n’y figure pas, dis-le clairement sans inventer. Ne complète jamais avec tes connaissances générales. »
Sauvegarde. L’agent est prêt.
Ce que ça fait vraiment
Les tests sur cette configuration (Mini PC Ubuntu, Intel i5, 16 Go de RAM) donnent des résultats concluants sur des documents de quelques pages à une vingtaine de pages. Le modèle cite ses sources, répond aux questions dans le périmètre des documents, et indique clairement quand une information est absente.
Quelques limites à connaître :
Documents texte uniquement. Les modèles testés ici (qwen2.5:3b et les autres) ne traitent pas les images. Envoyer une image depuis Open WebUI produit une erreur. Seul le texte extrait des PDF est utilisable par le RAG.
Les PDF scannés nécessitent une étape supplémentaire. Le moteur d’extraction par défaut d’Open WebUI ne sait pas lire un PDF image (un scan sans couche texte). Si tu essaies d’en déposer un dans une base de connaissances, tu obtiendras une erreur silencieuse ou un document vide. La solution est d’ajouter Tika – un service Apache open source – comme moteur d’extraction. Tika s’installe en container Docker séparé et se connecte à Open WebUI via le réseau Docker. Ce point fait l’objet d’un article à venir dans cette série.
Le system prompt fait la différence. Sans instruction explicite de rester dans les sources, le modèle complète avec ses connaissances générales – les réponses paraissent correctes mais ne s’appuient pas sur tes documents. L’instruction « réponds uniquement à partir des documents fournis » change significativement le comportement.
Les réponses ne sont pas déterministes. Le même modèle, la même question, des sessions différentes peuvent produire des réponses légèrement différentes. C’est une caractéristique fondamentale des LLM, pas un dysfonctionnement – et une bonne raison de tester systématiquement après chaque modification de configuration.
Pour aller plus loin
Cet article fait partie d’une série sur l’IA locale : Créer une IA locale et l’installation de logiciels en containers Docker sous ubuntu : Créer une IA locale

Commentaires récents