Tu veux faire tourner un modèle d’IA en local, sans envoyer tes données sur un serveur externe ? Ollama gère les modèles, Open WebUI fournit l’interface – les deux s’installent en quelques minutes via Portainer.
Prérequis
- Un PC sous Ubuntu avec Docker et Portainer installés (voir la série Ubuntu Projets)
- Les ports 11434 et 3000 disponibles
Vérifie les ports occupés avant de commencer :
sudo docker ps --format "table {{.Names}}\t{{.Ports}}"
Cette méthode fonctionne sur n’importe quel Ubuntu avec Docker et Portainer, que tu aies ou non d’autres containers en place. C’est pour faire fonctionner des modèles de langage qu’il peut être essentiel de réaliser cette installation sur un ordinateur un peu rapide, et pas trop occupé par d’autres activités. Les LLM consomment de l’espace disque pour leur stockage local (quelques giga octets par modèle) et de la mémoire vive lorsqu’ils sont utilisés (un ordinateur avec 8 Go de RAM minimum est recommandé, 16 Go si tu veux tester des modèles plus puissants).
Ce qu’on installe
Ollama est le moteur qui télécharge et fait tourner les modèles de langage (LLM). Il expose une API locale sur le port 11434. Il fonctionne en ligne de commande. Il ne stocke aucun historique de tes conversations.
Open WebUI est l’interface web qui se connecte à Ollama. Tu y accèdes depuis n’importe quel navigateur sur le même réseau local – PC Windows, tablette, Android. Open WebUI permet de disposer d’une interface de type « chat », pour « discuter » avec le LLM. Et Open WebUI assure le stockage de l’historique des conversations.
Les deux tournent en containers Docker séparés, avec leurs données dans /home/USER/docker/ pour être couverts par la sauvegarde automatique rclone (voir l’article sur la sauvegarde des containers).
Étape 1 – Installer Ollama
Créer le répertoire de config
bash
mkdir -p /home/USER/docker/ollama/config
Ce répertoire accueille tes fichiers de configuration personnalisés (Modelfiles). Les modèles eux-mêmes, qui peuvent peser plusieurs gigaoctets, sont stockés dans un volume Docker interne – ils ne sont pas sauvegardés, et se retéléchargent facilement si besoin.
Déployer la stack dans Portainer
Dans Portainer : Stacks > Add stack, donne le nom ollama, puis colle ce contenu dans le Web editor :
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
container_name: ollama
restart: unless-stopped
ports:
- "11434:11434"
volumes:
- ollama_models:/root/.ollama/models
- /home/USER/docker/ollama/config:/root/.ollama/config
environment:
- TZ=Europe/Paris
volumes:
ollama_models:
Remplace USER par ton nom d’utilisateur Linux, puis clique sur Deploy the stack.
Vérifier
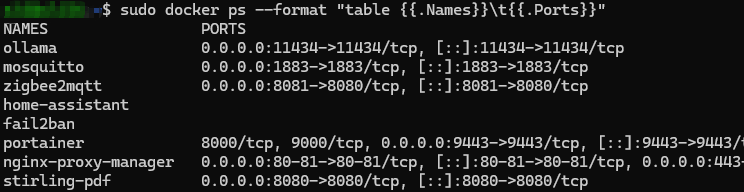
sudo docker ps --format "table {{.Names}}\t{{.Ports}}"
Le container ollama doit apparaître avec le port 11434 comme ici :
Étape 2 – Installer Open WebUI
Créer le répertoire de données
mkdir -p /home/USER/docker/open-webui/data
Déployer la stack dans Portainer
Dans Portainer : Stacks > Add stack, donne le nom open-webui, puis colle ce contenu :
version: '3.8'
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: unless-stopped
ports:
- "3000:8080"
volumes:
- /home/USER/docker/open-webui/data:/app/backend/data
environment:
- TZ=Europe/Paris
- OLLAMA_BASE_URL=http://ollama:11434
extra_hosts:
- "host.docker.internal:host-gateway"
networks:
- ollama_default
networks:
ollama_default:
external: true
Remplace USER par ton nom d’utilisateur Linux, puis clique sur Deploy the stack.
Le réseau
ollama_defaultest créé automatiquement par la première stack. Open WebUI s’y connecte pour joindre Ollama directement, sans passer par l’IP de la machine. C’est pour cette raison que les deux stacks doivent être déployées dans cet ordre.
Vérifier l’accès
Depuis n’importe quel navigateur sur ton réseau local :
http://IP_DU_PC_LINUX:3000
Tu dois voir l’interface Open WebUI. Le premier compte créé devient automatiquement administrateur – choisis un mot de passe solide.
Étape 3 – Télécharger un premier modèle
Dans Open WebUI, va dans Panneau d’administration > Réglages > Modèles, puis utilise l’option de téléchargement depuis Ollama pour récupérer un modèle.
Pour commencer, qwen2.5:3b est un bon choix : léger (environ 2,2 Go), rapide sur CPU, et d’excellente qualité en français.
Une fois téléchargé, ouvre une nouvelle conversation, sélectionne le modèle dans le menu déroulant en haut, et teste.
Ce qui est sauvegardé
| Élément | Emplacement | Sauvegardé |
|---|---|---|
| Config et Modelfiles Ollama | /home/USER/docker/ollama/config/ | Oui (rclone) |
| Données Open WebUI (historique, comptes) | /home/USER/docker/open-webui/data/ | Oui (rclone) |
| Modèles LLM | Volume Docker interne | Non – à retélécharger |
Les sauvegardes sont faites par rclone si vous avez fait la configuration indiquée plus haut (« ce qu’on installe »)
Pour aller plus loin
L’article suivant, Comparer 4 modèles LLM en local : le crash test en français, compare quatre modèles sur cette configuration via un protocole de test en français : logique, traduction idiomatique, créativité et charge CPU.

Commentaires récents