Tu veux savoir si une coupure de courant a eu lieu chez toi pendant ton absence, sans investir dans du matériel dédié ? Voici comment détecter une panne secteur avec des prises connectées Zigbee et Home Assistant, et recevoir une alerte par e-mail à chaque coupure et à chaque retour du courant.
Cet article s’inscrit dans la série Domotique avec Home Assistant et réutilise l’infrastructure mise en place dans la série Projets Ubuntu (Docker, Portainer, Zigbee2MQTT).
Le matériel utilisé
Un mini PC Ubuntu, protégé par un onduleur, faisant tourner Home Assistant, Mosquitto et Zigbee2MQTT en containers Docker
Un dongle Zigbee (Sonoff MG21)
Cinq prises connectées Zigbee Nous A7Z, chacune alimentant un appareil différent de la maison (dont le réfrigérateur et le congélateur, dont la charge constante en fait de bons indicateurs)
Un Chromecast Audio, connecté en Wi-Fi
L’idée : si tous ces appareils disparaissent du réseau en même temps, c’est qu’il n’y a plus de courant dans la maison. Le mini PC et sa box internet, eux, restent en ligne grâce à l’onduleur.
Demander à Zigbee2MQTT de vérifier activement le réseau
Sans réglage supplémentaire, une prise Zigbee débranchée, ou sans courant, ne passe jamais à indisponible : Zigbee2MQTT ne vérifie pas activement, par défaut, si un appareil alimenté sur secteur répond encore. Il se contente d’afficher la dernière valeur reçue, indéfiniment, tant qu’aucun nouveau message n’arrive. Pour une prise débranchée, ça veut dire un blocage permanent sur son dernier état connu.
Il faut donc activer la fonctionnalité de vérification de disponibilité de Zigbee2MQTT, qui va interroger (ping) les prises à intervalles réguliers pour confirmer qu’elles répondent encore.
Piège à éviter : ce réglage ne doit jamais être fait en éditant directement le fichier configuration.yaml de Zigbee2MQTT à la main. Zigbee2MQTT garde sa configuration active en mémoire et la réécrit sur le fichier physique à chaque redémarrage du container, ce qui efface silencieusement toute modification manuelle qui n’a pas été prise en compte par le service lui-même.
Le bon réglage passe par l’interface Web de Zigbee2MQTT :
Va dans Paramètres > Disponibilité
Active la case « Activer les vérifications de disponibilité »
Dans la section Active, renseigne un timeout (en minutes). Trois minutes est un bon compromis entre rapidité de détection et charge sur le dongle Zigbee
Enregistre
Ce réglage global s’applique à tous les appareils Zigbee alimentés sur secteur (comme les prises), sans qu’il soit nécessaire d’activer quoi que ce soit individuellement pour chacune.
Une fois activé, débranche une prise et observe sa fiche dans le frontend de Zigbee2MQTT : après le délai configuré, elle passe à « Disponibilité : Désactivé ». Côté Home Assistant, l’entité switch correspondante passe à indisponible au même moment, ce qui fait automatiquement basculer le capteur de groupe.
Sécuriser l’envoi d’e-mail
Avant de configurer l’envoi d’alertes, un point de sécurité important : n’utilise jamais un compte e-mail personnel ou professionnel pour ce genre d’automatisation. Si ce compte est compromis un jour, l’impact reste limité à cette seule automatisation.
La bonne pratique consiste à créer un compte Gmail secondaire, dédié uniquement à l’envoi de ces alertes, avec un mot de passe d’application (pas le mot de passe du compte lui-même). Tout le détail de cette mise en place, avec l’activation de la double authentification (mais pas la création du mot de passe d’application), fait l’objet d’un article séparé : Sécuriser son compte Gmail avec la double authentification et Aegis Authenticator.
Une fois le mot de passe d’application créé, tous les identifiants (mot de passe, adresse expéditrice, adresse destinataire) sont stockés dans secrets.yaml, jamais directement dans configuration.yaml, pour ne jamais les exposer si tu partages ta configuration.
Dans /home/USER/docker/home-assistant/config/secrets.yaml :
Après modification, redémarre complètement le container Home Assistant : ce type de service (notify) n’est pas pris en compte par un simple rechargement de configuration.
Pour tester, va dans Outils de développement > Actions, cherche notify.email_alertes, renseigne un message, et lance l’action. Vérifie ta boîte de réception, y compris le dossier spam : un premier envoi automatisé depuis une adresse encore peu utilisée y atterrit parfois. Marquer le message comme « non spam » et ajouter l’adresse aux contacts résout le problème pour la suite.
Créer les capteurs template et le groupe
Le Chromecast Audio se comporte différemment des prises Zigbee : c’est un appareil Wi-Fi, dont Home Assistant détecte lui-même la perte de connexion en quelques secondes, sans configuration particulière à ajouter côté réseau. Son entité media_player passe directement à indisponible en cas de coupure.
Les prises Zigbee, elles, ont besoin d’un réglage supplémentaire détaillé dans la section suivante avant de se comporter de la même façon. On va surveiller la présence de chaque appareil sur le réseau Zigbee, pas sa consommation. Home Assistant expose pour chaque prise Zigbee une entité switch, qui représente son état de connexion. Tant que la prise répond, cette entité a une valeur (on ou off, selon que la prise est allumée ou éteinte manuellement). Si la prise ne répond plus, l’entité passe à indisponible.
On crée d’abord un capteur « template » par appareil : des capteurs virtuels qui traduisent l’état de chaque appareil en on ou off, selon qu’il est présent ou non sur le réseau. Puis on les regroupe en un seul capteur, qui résume l’état du secteur pour toute la maison.
À ajouter dans configuration.yaml :
template:
- binary_sensor:
- name: "Courant Prise A Bureau"
unique_id: courant_prise_a_bureau
device_class: power
state: >
{{ states('switch.prise_a_bureau_entree') != 'unavailable' }}
- name: "Courant Prise B Salon"
unique_id: courant_prise_b_salon
device_class: power
state: >
{{ states('switch.prise_b_salon_tel') != 'unavailable' }}
- name: "Courant Prise C Garage"
unique_id: courant_prise_c_garage
device_class: power
state: >
{{ states('switch.prise_c_garage_machine_a_laver') != 'unavailable' }}
- name: "Courant Chromecast Salon"
unique_id: courant_chromecast_salon
device_class: power
state: >
{{ states('media_player.salon') != 'unavailable' }}
- name: "Courant Prise D Frigo"
unique_id: courant_prise_d_frigo
device_class: power
state: >
{{ states('switch.prise_d_frigo') != 'unavailable' }}
- name: "Courant Prise E Congélateur"
unique_id: courant_prise_e_congelateur
device_class: power
state: >
{{ states('switch.prise_e_congelateur') != 'unavailable' }}
binary_sensor:
- platform: group
name: "Courant Secteur Maison"
unique_id: courant_secteur_maison
entities:
- binary_sensor.courant_prise_a_bureau
- binary_sensor.courant_prise_b_salon
- binary_sensor.courant_prise_c_garage
- binary_sensor.courant_chromecast_salon
- binary_sensor.courant_prise_d_frigo
- binary_sensor.courant_prise_e_congelateur
Remplace switch.prise_a_bureau_entree et les autres par les identifiants exacts de tes propres prises. Tu les trouves dans Outils de développement > États, en filtrant sur switch..
Le groupe fonctionne en logique « au moins un » : il reste à on tant qu’un seul des appareils listés est présent sur le réseau, et ne passe à off que si tous sont indisponible en même temps. C’est ce qui permet de distinguer une vraie coupure générale d’un simple appareil débranché ou en panne.
Pour ajouter une prise supplémentaire plus tard, il suffit de dupliquer un bloc de capteur template avec le bon identifiant, et d’ajouter la ligne correspondante dans entities: du groupe. Rien d’autre à modifier : ni le service notify, ni les automatisations, qui s’appuient uniquement sur le capteur de groupe.
Activer le ping de disponibilité sur Zigbee2MQTT
Sans réglage supplémentaire, une prise Zigbee débranchée ne passe jamais à indisponible : Zigbee2MQTT ne vérifie pas activement, par défaut, si un appareil alimenté sur secteur répond encore. Il se contente d’afficher la dernière valeur reçue, indéfiniment, tant qu’aucun nouveau message n’arrive. Pour une prise débranchée, ça veut dire un blocage permanent sur son dernier état connu.
Il faut donc activer la fonctionnalité de vérification de disponibilité de Zigbee2MQTT, qui va interroger (ping) les prises à intervalles réguliers pour confirmer qu’elles répondent encore.
Piège à éviter : ce réglage ne doit jamais être fait en éditant directement le fichier configuration.yaml de Zigbee2MQTT à la main. Zigbee2MQTT garde sa configuration active en mémoire et la réécrit sur le fichier physique à chaque redémarrage du container, ce qui efface silencieusement toute modification manuelle qui n’a pas été prise en compte par le service lui-même.
Le bon réglage passe par l’interface Web de Zigbee2MQTT :
Va dans Paramètres > Disponibilité
Active la case « Activer les vérifications de disponibilité »
Dans la section Active, renseigne un timeout (en minutes). Trois minutes est un bon compromis entre rapidité de détection et charge sur le dongle Zigbee
Enregistre
Ce réglage global s’applique à tous les appareils Zigbee alimentés sur secteur (comme les prises), sans qu’il soit nécessaire d’activer quoi que ce soit individuellement pour chacune.
Une fois activé, débranche une prise et observe sa fiche dans le frontend de Zigbee2MQTT : après le délai configuré, elle passe à « Disponibilité : Désactivé ». Côté Home Assistant, l’entité switch correspondante passe à indisponible au même moment, ce qui fait automatiquement basculer le capteur de groupe.
Les automatisations
Deux automatisations : une pour signaler le début d’une coupure, une pour signaler le retour du courant. Toutes deux intègrent un délai de 30 secondes avant de se déclencher, pour éviter une alerte sur une micro-coupure sans conséquence.
À ajouter dans /home/USER/docker/home-assistant/config/automations.yaml :
- id: alerte_debut_panne_courant
alias: "Alerte début de panne de courant"
trigger:
- platform: state
entity_id: binary_sensor.courant_secteur_maison
to: "off"
for:
seconds: 30
action:
- service: notify.email_alertes
data:
title: "[home ALD] Coupure de courant détectée"
message: >
Une coupure de courant a été détectée à {{ now().strftime('%H:%M:%S') }}.
Ce mail a été généré automatiquement par Home Assistant d'Anne-Laure, suite à l'automatisation id: alerte_debut_panne_courant.
- id: alerte_fin_panne_courant
alias: "Alerte fin de panne de courant"
trigger:
- platform: state
entity_id: binary_sensor.courant_secteur_maison
to: "on"
for:
seconds: 30
action:
- service: notify.email_alertes
data:
title: "[home ALD] Retour du courant"
message: >
Le courant est revenu à {{ now().strftime('%H:%M:%S') }}.
Ce mail a été généré automatiquement par Home Assistant d'Anne-Laure, suite à l'automatisation id: alerte_fin_panne_courant.
Deux détails utiles à reproduire, indépendamment du sujet de l’automatisation :
Un préfixe cohérent dans le titre (ici [home ALD]) permet de créer facilement un filtre ou une étiquette dans ta messagerie pour regrouper toutes les alertes de ta maison connectée
Une ligne de traçabilité dans le corps du message, citant l’identifiant de l’automatisation à l’origine de l’envoi, facilite le diagnostic si tu dois un jour retrouver quelle automatisation a déclenché quel e-mail
Après modification, recharge les automatisations (Outils de développement > YAML > Recharger les automatisations), ou redémarre complètement Home Assistant si tu préfères.
Bilan des tests réels
Le test décisif consiste à débrancher réellement les appareils concernés, plutôt que de forcer un état depuis l’interface, pour valider le comportement de bout en bout.
En débranchant une seule prise, rien ne se passe : le groupe reste alimenté grâce aux autres appareils encore présents sur le réseau, exactement le comportement attendu. En débranchant tous les appareils, le capteur de groupe passe à indisponible, et l’e-mail de coupure arrive environ 30 secondes après la détection effective par Zigbee2MQTT, conformément au délai configuré dans l’automatisation.
Au rebranchement, le Chromecast est détecté quasiment tout de suite (c’est un appareil Wi-Fi). Les prises Zigbee, elles, réapparaissent en quelques minutes au maximum, le temps que Zigbee2MQTT confirme leur présence lors de son prochain cycle de vérification.
J’ai récemment entrepris de sécuriser l’ensemble de mes comptes en ligne – Google, stockage cloud, messagerie. Ce que j’ai découvert en chemin m’a surprise : ma configuration de départ, que je croyais raisonnable, était en réalité fragile à plusieurs endroits. Cet article retrace la démarche et les principes qui m’ont guidée. Je ne peux pas en détailler toutes les étapes comme je le fais habituellement – la nature même du sujet impose de ne pas trop exposer ses choix techniques. Mais les principes, eux, sont utiles à partager.
Mon point de départ – et ses problèmes
Mon point de départ : un compte Google professionnel et un compte Google personnel, chacun configuré avec un mot de passe plutôt solide et l’adresse de l’autre pour une éventuelle récupération.
Le seul point positif : les mots de passe étaient stockés dans un gestionnaire de mots de passe.
Ce système posait plusieurs problèmes :
Circularité des deux comptes : si quelqu’un prend le contrôle de l’un des deux comptes, il accède immédiatement à l’autre via la récupération. Les deux comptes tombent ensemble.
Absence de second verrou : si quelqu’un accédait à mon mot de passe, il pouvait accéder à mon compte puis à l’autre. La solution : mettre en place la double authentification avec une application indépendante de toute plateforme, qui fonctionne sans connexion réseau.
un ordinateur portable avec des disques durs non chiffrés, que n’importe qui aurait pu lire.
si je n’avais plus accès à mon téléphone, je me retrouvais dépourvue de toute information pour agir.
Voici les solutions adoptées pour résoudre successivement ces problèmes.
Limiter le « blast radius »
Il faut tout faire pour que la compromission d’un seul compte n’ait pas d’impact sur les autres. C’est le principe de limitation du « blast radius » – le rayon de l’explosion.
On évite donc les adresses de récupération croisées : si l’adresse A est l’adresse de récupération de l’adresse B, alors l’adresse de récupération de l’adresse A doit être une adresse C indépendante – pas l’adresse B. Sinon, si quelqu’un prend le contrôle de l’un des deux comptes, il accède immédiatement à l’autre. Les deux tombent ensemble.
Pour les mêmes raisons, les mots de passe des différentes adresses doivent être différents, et on ne stocke pas de données sensibles dans un compte secondaire – les mots de passe d’autres comptes, par exemple.
La double authentification : choisir une application indépendante
Mais cette solution crée une nouvelle dépendance : si je perdais l’accès à mon téléphone (perte, vol, casse), je perdais l’accès à tous les comptes protégés par l’application d’authentification. Les codes de secours sont la réponse à ce problème.
Les codes de secours : prévoir la perte du téléphone
Les codes de secours donnent accès aux comptes protégés même si le téléphone ne peut plus servir : des codes à usage unique, générés par chaque service au moment de l’activation de la 2FA, qui te permettent de te connecter sans téléphone. Chaque code ne peut être utilisé qu’une seule fois.
Quelques principes pour les stocker correctement :
Les copies doivent être indépendantes les unes des autres. Si tous tes codes de secours sont sur Google Drive et que tu perds l’accès à ton compte Google, tu perds aussi les codes qui auraient pu te permettre de le récupérer. Utilise au moins un service de stockage indépendant de Google pour cette copie.
Les copies doivent être géographiquement séparées. Une copie à domicile et une copie ailleurs – chez une personne de confiance, dans un coffre, sur un service cloud accessible depuis n’importe où. Un incendie ou un cambriolage ne doit pas effacer toutes tes copies en même temps.
Une copie papier reste utile. Dans un scénario où tu n’as plus accès à aucun appareil ni à aucun service en ligne, un bout de papier chez une personne de confiance peut être ce qui te permet de tout récupérer.
Note que tous les services ne proposent pas de codes de secours. C’est un critère à prendre en compte : un service qui gère des données importantes et ne propose pas de codes de secours t’expose à une perte d’accès définitive si tu perds ton téléphone.
Chiffrer son ordinateur portable
Un portable volé, c’est potentiellement toutes tes données exposées – y compris les sessions ouvertes, les mots de passe en cache dans les navigateurs, les fichiers temporaires. Le chiffrement du disque rend ces données illisibles sans le bon mot de passe, même si quelqu’un retire le disque et le branche ailleurs.
Un point souvent négligé : si ton ordinateur a deux disques, chiffre les deux – en commençant par le disque qui contient Windows. Le disque système contient bien plus de données sensibles qu’il n’y paraît, même si tous tes fichiers personnels sont sur le second disque.
La personne de confiance et la procédure d’urgence
Tous les systèmes de récupération décrits jusqu’ici supposent que tu peux accéder à quelque chose : un service cloud, un gestionnaire de mots de passe, un appareil. Mais dans un scénario extrême – perte simultanée du téléphone, de l’ordinateur et de l’accès à internet – il faut un dernier filet.
Ce filet, c’est une personne de confiance à qui tu as remis les informations minimales pour t’aider à récupérer l’accès à tes comptes essentiels : codes de secours imprimés, procédure claire expliquant quoi faire et dans quel ordre.
Cette procédure doit être rédigée pour quelqu’un qui n’est pas technicien – elle doit être compréhensible et actionnable sans contexte. Elle doit aussi prévoir un moyen de vérifier l’identité de la personne qui appelle, pour éviter qu’un attaquant ne se fasse passer pour toi.
Les informations les plus sensibles – mots de passe, clés de récupération, informations bancaires – méritent d’être séparées du reste, dans une enveloppe scellée distincte, avec une recommandation de la conserver dans un coffre.
Ce que cette démarche ne couvre pas
Cette démarche se concentre sur les comptes en ligne et l’ordinateur portable. Elle ne couvre pas :
La sécurisation des appareils mobiles (code PIN, chiffrement Android ou iOS)
La gestion des mots de passe eux-mêmes – un gestionnaire de mots de passe (1Password, Bitwarden, Dashlane ou KeePass) est un prérequis implicite à tout ce qui est décrit ici
La sécurité du réseau domestique (routeur, Wi-Fi)
Les sauvegardes de données – un sujet distinct, tout aussi important
Ces sujets ont chacun leur propre complexité et mériteraient des articles dédiés.
Un ordinateur portable volé, c’est d’abord des données personnelles exposées. BitLocker, intégré à Windows, chiffre le contenu de tes disques pour les rendre illisibles sans le bon mot de passe – même si quelqu’un retire le disque dur et le branche sur un autre ordinateur.
Ce que BitLocker protège – et ce qu’il ne protège pas
BitLocker protège les données au repos : quand l’ordinateur est éteint ou verrouillé, le contenu des disques est illisible sans la clé de déchiffrement. Un voleur qui récupère ton portable éteint ne peut rien faire des données.
En revanche, BitLocker ne protège pas un ordinateur allumé et déverrouillé. Si quelqu’un accède à ta session Windows ouverte, il accède aussi à tes fichiers. Le chiffrement du disque ne remplace pas un mot de passe de session solide et l’habitude de verrouiller son écran quand on s’éloigne.
Prérequis
BitLocker est disponible sur Windows 10 et Windows 11 en versions Pro, Entreprise et Éducation. Il n’est pas disponible sur les versions Home.
Pour vérifier ta version de Windows : clique droit sur le menu Démarrer > « Système » > regarde la ligne « Édition Windows ».
Il te faut aussi les droits administrateur sur l’ordinateur pour activer BitLocker.
Pourquoi commencer par le disque qui contient Windows (C:)
Même si tu ranges tous tes fichiers personnels sur un second disque, ton disque C: contient bien plus de données sensibles qu’il n’y paraît :
Les mots de passe enregistrés dans les navigateurs (Chrome, Firefox, Edge) sont stockés sur C:
Les sessions de messagerie et leurs jetons de connexion sont sur C: – un accès à ce disque peut suffire à ouvrir tes boîtes mail sans connaître tes mots de passe
Tout ce qui passe par le dossier Téléchargements atterrit par défaut sur C:
Windows utilise C: comme mémoire temporaire : si tu ouvres un document confidentiel depuis D:, Windows peut en copier des fragments sur C:
Il faut donc toujours commencer par chiffrer C:, et ensuite seulement s’occuper des autres disques.
Chiffrer le disque principal (C:)
Ouvrir le gestionnaire BitLocker
Dans le menu Démarrer, tape « BitLocker » et clique sur « Gérer BitLocker ». Tu arrives sur une page qui liste tous les disques de ton ordinateur.
Activer BitLocker sur C:
Clique sur « Activer BitLocker » à côté du lecteur C:. Windows lance un assistant en plusieurs étapes.
Sauvegarder la clé de récupération
C’est l’étape la plus importante. Windows te propose plusieurs options pour sauvegarder la clé de récupération – un code à 48 chiffres qui te permet de déverrouiller le disque si quelque chose se passe mal au démarrage.
Si ton ordinateur est lié à un compte Microsoft, tu peux choisir « Enregistrer sur mon compte Microsoft » : la clé sera accessible depuis account.microsoft.com > Appareils > Clés de récupération BitLocker.
Si ton ordinateur n’est pas lié à un compte Microsoft (ce qui est tout à fait possible et même recommandé pour des raisons de confidentialité), cette option n’est pas disponible. Dans ce cas :
Choisis « Enregistrer dans un fichier » et sauvegarde ce fichier sur un emplacement extérieur au disque C: en cours de chiffrement – une clé USB, un autre disque, ou un dossier cloud accessible depuis un autre appareil
Tu peux aussi choisir « Imprimer la clé de récupération » pour en avoir une copie papier
Note l’identifiant de clé affiché (une suite de caractères du type 85CDA21F-...) : il te permettra de retrouver la bonne clé si tu en as plusieurs. Conserve cette clé précieusement dans un endroit sûr, séparé de l’ordinateur – idéalement chez une personne de confiance ou dans un gestionnaire de mots de passe accessible hors ligne.
Choisir quoi chiffrer
Windows te demande si tu veux chiffrer uniquement l’espace utilisé ou tout le disque. Choisis « Chiffrer tout le lecteur » si l’ordinateur est utilisé depuis un moment – c’est plus long mais plus complet.
Choisir le mode de chiffrement
Choisis « Nouveau mode de chiffrement » si ton ordinateur tourne sous Windows 10 ou 11 – c’est le mode le plus récent et le plus solide.
Lancer le chiffrement
Clique sur « Démarrer le chiffrement ». Le processus se lance immédiatement en arrière-plan – tu peux continuer à utiliser l’ordinateur pendant ce temps. La durée dépend de la taille du disque et peut aller de quelques minutes à plusieurs heures.
Windows te demandera peut-être de redémarrer pour terminer le chiffrement.
Chiffrer un second disque (D:)
Une fois le disque C: chiffré, retourne dans le gestionnaire BitLocker et clique sur « Activer BitLocker » à côté de ton second disque.
Cette fois, Windows te demande de définir un mot de passe pour déverrouiller ce disque. Choisis un mot de passe solide et note-le dans ton gestionnaire de mots de passe.
Sauvegarde la clé de récupération de ce second disque – elle est différente de celle du disque C:. Conserve-la avec le même soin, en indiquant clairement de quel disque elle provient.
Déverrouillage automatique
À la fin de la procédure, BitLocker peut te proposer d’activer le déverrouillage automatique de ce disque quand tu ouvres une session Windows. Si cette option est disponible, coche-la : le disque D: s’ouvrira automatiquement à chaque démarrage, sans que tu aies à saisir son mot de passe.
Si cette option n’est pas proposée, tu devras saisir le mot de passe du disque D: à chaque démarrage, ou l’activer manuellement plus tard depuis le gestionnaire BitLocker.
Un point important : si le disque D: est un disque amovible ou s’il est séparé physiquement du disque C: (par exemple après un remplacement de disque), le déverrouillage automatique ne fonctionnera plus. Dans ce cas, tu auras besoin du mot de passe ou de la clé de récupération spécifique à ce disque pour y accéder.
Vérifier que tout fonctionne
Redémarre l’ordinateur. Si le démarrage se passe normalement et que tu accèdes à ta session Windows comme d’habitude, le chiffrement est en place et fonctionne correctement.
Pour confirmer : ouvre le gestionnaire BitLocker. Chaque disque chiffré doit afficher « BitLocker activé ».
Pour aller plus loin
BitLocker protège tes données en cas de vol physique de l’ordinateur. C’est une brique importante, mais elle s’inscrit dans une démarche de sécurisation plus large : mots de passe solides, double authentification sur tes comptes en ligne, sauvegardes régulières.
Un mot de passe seul ne suffit plus pour protéger un compte en ligne. La double authentification (2FA) ajoute un second verrou, et une application dédiée comme Aegis Authenticator est bien plus fiable qu’un SMS pour le gérer.
Ce guide part du principe que tu utilises un gestionnaire de mots de passe pour stocker tes identifiants et mots de passe de façon sécurisée. Si ce n’est pas encore le cas, c’est le bon moment pour en adopter un : 1Password, Bitwarden, Dashlane ou KeePass sont parmi les options les plus connues. Sans gestionnaire de mots de passe, il est très difficile de suivre les bonnes pratiques décrites ici.
Pourquoi la double authentification, et pourquoi pas le SMS
La double authentification repose sur un principe simple : pour te connecter, tu dois fournir deux preuves d’identité. La première est ton mot de passe, que tu connais. La seconde est un code temporaire, valable 30 secondes, généré par un appareil que tu possèdes – ton téléphone.
Même si quelqu’un vole ou devine ton mot de passe, il ne peut pas se connecter sans ce second code.
Google propose plusieurs méthodes pour recevoir ce code :
Un SMS envoyé sur ton numéro de téléphone
Une notification sur un appareil Google déjà connecté
Un code généré par une application d’authentification
Le SMS est la méthode la plus connue, mais aussi la plus fragile : un SMS peut être intercepté, et si tu perds ton téléphone, tu perds aussi l’accès à tes comptes. Une application d’authentification est plus robuste : elle fonctionne sans connexion réseau, et ses sauvegardes sont sous ton contrôle.
Choisir et installer Aegis Authenticator
Aegis Authenticator est une application Android gratuite et open source, développée par Beem Development. Elle gère les codes 2FA pour tous tes comptes, les stocke de façon chiffrée sur ton téléphone, et permet d’en faire des sauvegardes.
Google propose sa propre application d’authentification, Google Authenticator. Le problème : elle dépend de l’infrastructure Google. Si Google rencontre une panne ou un problème d’accès, Google Authenticator peut devenir inutilisable au moment précis où tu en as besoin. Aegis est indépendant de toute plateforme – il fonctionne sans connexion réseau et sans dépendre d’aucun service tiers.
Installation
Ouvre le Play Store et cherche « Aegis Authenticator ». Fais attention : une version sponsorisée apparaît souvent en premier dans les résultats. Vérifie que le développeur est bien « Beem Development » avant d’installer.
Aegis Authenticator fonctionne uniquement sur Android.
Premier lancement
Au premier lancement, Aegis te demande de choisir une méthode de protection :
Choisis « Mot de passe et données biométriques » (empreinte digitale ou reconnaissance faciale selon ton téléphone)
Tu définis un mot de passe qui chiffre l’ensemble de tes codes 2FA
Ce mot de passe est critique : si tu le perds, tu perds l’accès à tous tes codes. Note-le immédiatement dans un gestionnaire de mots de passe.
Nota
Si tu avais Google Authenticator installé sur ton téléphone avant de passer à Aegis, supprime-le de ton compte Google dans les paramètres de sécurité, puis reconfigure Aegis en scannant un nouveau QR code. Si tu as les deux applications en parallèle, ça peut créer de la confusion.
Activer la 2FA sur un compte Google
Étape 1 – Accéder aux paramètres de sécurité
Depuis un PC, connecte-toi à ton compte Google et va sur myaccount.google.com. Clique sur « Sécurité » dans le menu de gauche.
Si ton mot de passe n’a pas été changé depuis longtemps, ou s’il est trop simple, commence par le mettre à jour : clique sur « Mot de passe », saisis l’ancien, puis le nouveau deux fois. Conserve ce mot de passe dans ton gestionnaire de mots de passe.
Étape 2 – Ouvrir la validation en deux étapes
Dans la section « Comment vous connecter à Google », clique sur « Validation en deux étapes ». Google te demande de saisir ton mot de passe pour confirmer.
Sur la page qui s’affiche, Google propose plusieurs méthodes. Cherche « Application d’authentification » et clique dessus. Les instructions mentionnent Google Authenticator, mais elles fonctionnent exactement de la même façon avec Aegis.
Étape 4 – Scanner le QR code avec Aegis
Google affiche un QR code à l’écran. Sur ton téléphone, ouvre Aegis et appuie sur le bouton « + » en bas à droite. Choisis « Scanner un QR code » et pointe la caméra vers l’écran.
Aegis ajoute automatiquement l’entrée pour ton compte Google et commence à générer des codes à 6 chiffres, renouvelés toutes les 30 secondes.
Étape 5 – Valider et activer
Saisis dans le champ prévu le code à 6 chiffres affiché par Aegis au moment de la saisie. Google confirme que l’application est bien configurée.
Clique ensuite sur « Activer » pour finaliser la validation en deux étapes.
Le piège « Google Authenticator » au moment de la connexion
Une fois la 2FA activée, tu vas rencontrer une subtilité au moment de te connecter.
Après avoir saisi ton mot de passe, Google affiche parfois un écran qui demande un « code de sécurité » à 10 chiffres, avec le message « accédez à g.co/sc ». Ce code est généré automatiquement par google – ce n’est pas un code Aegis.
Pour utiliser Aegis, clique sur « Essayer une autre méthode » (lien discret en bas de l’écran), puis choisis « Application d’authentification (Google Authenticator) ». C’est là que tu saisis le code à 6 chiffres affiché par Aegis. J’ai mis du temps à comprendre ça et j’ai cru que j’allais perdre l’accès à mon compte….
Les codes de secours
Dès que la 2FA est activée, Google te propose de générer des codes de secours. Ne saute pas cette étape.
Les codes de secours sont des codes à usage unique, au format texte, qui te permettent de te connecter si tu n’as plus accès à Aegis – téléphone perdu, cassé, volé. Chaque code ne peut être utilisé qu’une seule fois.
Générer et stocker les codes
Dans les paramètres de sécurité de ton compte Google, section « Validation en deux étapes », clique sur « Codes de secours » puis « Générer des codes ». Google affiche une liste de 10 codes.
Copie-les dans ton gestionnaire de mots de passe, dans l’entrée dédiée à ce compte Google. Télécharge aussi le fichier texte proposé par Google.
Où stocker ce fichier
Ce fichier doit être accessible même si tu n’as plus ton téléphone, ton PC, ou ta connexion internet habituelle. Quelques règles de base :
Ne le stocke pas uniquement sur Google Drive : si tu perds l’accès à ton compte Google, tu perds aussi l’accès à Google Drive
Utilise un second service de stockage cloud, indépendant de Google, dans un dossier dédié à la sécurité
Conserve aussi une copie papier dans un endroit sûr, idéalement chez une personne de confiance
Certains sites ne proposent pas de codes de secours. Dans ce cas, la seule option de récupération est le SMS ou un autre appareil de confiance. C’est un critère important pour évaluer le niveau de sécurité d’un service : un site qui gère des fichiers ou des données sensibles devrait proposer des codes de secours.
Configurer la sauvegarde chiffrée d’Aegis
Aegis stocke tes codes 2FA sur ton téléphone. Si tu perds ce téléphone sans avoir fait de sauvegarde, tu perds tous tes codes.
Activer la sauvegarde automatique
Dans Aegis, ouvre les paramètres (icône en haut à droite) et va dans « Sauvegardes ». Active la sauvegarde automatique et choisis un emplacement sur le stockage interne du téléphone – par exemple un dossier AEGIS dans le répertoire Documents.
Configure le nombre de versions à conserver (5 est une valeur raisonnable) : Aegis garde les fichiers les plus récents et supprime les plus anciens automatiquement.
Le mot de passe de la sauvegarde
La sauvegarde est chiffrée par défaut avec un mot de passe qui peut être différent de celui de l’application Aegis elle-même. Note ce mot de passe dans ton gestionnaire de mots de passe avec un nom clair, par exemple « aegis-sauvegarde-mot-de-passe ». Tu en auras besoin pour restaurer Aegis sur un nouvel appareil.
Copier la sauvegarde ailleurs
Le fichier de sauvegarde (au format .json) doit aussi être copié en dehors du téléphone. La méthode la plus simple : depuis l’application Fichiers de ton téléphone, sélectionne le dernier fichier de sauvegarde, appuie sur « Partager » et envoie-le vers ton service de stockage cloud secondaire, dans le même dossier que tes codes de secours.
À refaire à chaque fois que tu ajoutes un nouveau compte dans Aegis.
Étendre la 2FA à d’autres comptes
La même procédure s’applique à la grande majorité des services en ligne qui proposent la 2FA : aller dans les paramètres de sécurité du compte, choisir « Application d’authentification », scanner le QR code avec Aegis, valider avec le code à 6 chiffres.
Prenons l’exemple de Dropbox. Dans les paramètres Dropbox, section « Sécurité », active la « Vérification en deux étapes » et choisis « Utiliser une application mobile ». Scanne le QR code avec Aegis, saisis le code de confirmation. Dropbox propose des codes de secours à la fin de la procédure – génère-les et stocke-les comme pour Google.
Quelques points à retenir quand tu actives la 2FA sur un nouveau service :
Tous les sites ne proposent pas de codes de secours. Certains n’offrent que le SMS comme solution de secours. Dans ce cas, assure-toi que ton numéro de téléphone est à jour sur le compte.
Certains services permettent de choisir entre SMS et application d’authentification. Préfère toujours l’application quand c’est possible.
Certains services cloud n’acceptent pas d’application tierce d’authentification. Dans ce cas suis leurs instructions.
Après chaque activation, fais une copie de sauvegarde d’Aegis : le fichier de sauvegarde doit inclure le nouveau compte.
Pour aller plus loin
Ce guide couvre l’activation de la 2FA sur un compte Google et les principes généraux pour l’étendre à d’autres services. La double authentification est une brique parmi d’autres dans une démarche de sécurisation complète : gestion des sauvegardes, procédures de récupération en cas de perte du téléphone, compartimentation des comptes.
J’ai construit, avec une IA, une application qui décompose n’importe quelle image en suivant les trajectoires d’un attracteur, une figure née d’équations différentielles. Le mode d’emploi complet est sur la page d’aide, ici je raconte ce que cette décomposition change dans le regard qu’on porte sur une image.
Qu’est-ce qu’un attracteur étrange
Un attracteur étrange est une figure mathématique qui naît d’un système de trois équations différentielles : des formules qui indiquent, à chaque instant, dans quelle direction se déplace un point de l’espace. Répète ce calcul des milliers de fois et les points dessinent une trajectoire qui ne se referme jamais tout à fait sur elle-même, sans jamais non plus partir dans n’importe quelle direction. C’est cette tension entre ordre et imprévisibilité qui a donné son nom à la théorie du chaos, popularisée par l’attracteur de Lorenz et son fameux papillon à deux ailes.
Dans l’application, chaque pixel de ton image devient un point qui suit sa propre trajectoire sur l’un de ces systèmes. Tu peux choisir parmi cinq attracteurs, Aizawa, Thomas, Lorenz, Halvorsen ou Rössler, chacun avec sa dynamique propre. Le détail de chacun est dans la page d’aide, ce qui m’intéresse ici, c’est ce que ce mouvement fait à une image.
Une image qu’on regarde autrement
Une photo, une fois chargée, reste d’abord parfaitement nette. Puis, à mesure que tu avances dans le temps de la simulation, une zone commence à se décoller, pixel par pixel, et chaque pixel garde sa couleur d’origine tout en partant sur sa propre trajectoire. Le résultat n’est ni l’image de départ ni un nuage abstrait, c’est un état intermédiaire où on reconnaît encore le sujet dans les zones intactes, pendant que les zones parties dessinent quelque chose de nouveau.
Ce qui m’a surprise, c’est à quel point cet entre-deux change la lecture d’une image. Un visage, un paysage, un objet familier, on ne le voit plus de la même façon quand une partie de sa matière s’est mise à voler. L’image garde son identité tout en devenant autre chose. C’est cet instant précis, ni la photo de départ ni le nuage final, que l’application permet de figer et d’explorer, en avançant ou reculant dans le temps avec un simple curseur.
Le blanc qui mange les couleurs
Un problème est apparu en travaillant sur de vraies images : dans les zones denses, là où beaucoup de fils du même attracteur se superposent, les couleurs s’écrasaient vers le blanc. La cause est physique, pas un bug : les fils s’affichent en lumière additive, et là où des centaines d’entre eux se croisent, les trois canaux de couleur saturent à leur maximum, ce qui donne du blanc, quelle que soit la couleur d’origine des pixels.
La solution a demandé trois ajustements combinés : baisser l’opacité de chaque fil pour repousser le seuil de saturation, renforcer légèrement la saturation des couleurs pour qu’elles résistent mieux à l’addition, et ajouter un curseur, Intensité des fils, pour doser ce réglage selon chaque image. Aucun pixel n’est perdu dans l’opération, seule la façon dont ils se superposent visuellement change. C’est un bon exemple de contrainte technique qui, une fois résolue, devient un outil créatif : ce curseur permet de choisir entre une image aérée aux couleurs franches et une image dense et lumineuse.
Une usine artistique
Une fois l’image chargée et l’attracteur choisi, chaque instant de la simulation est une composition possible. Le bouton Prendre une photo exporte cet instant en haute définition, 3840 pixels de large, et surtout nomme le fichier avec la recette complète de l’image : l’attracteur utilisé, la position dans le temps, le délai de départ, la taille de la zone initiale, la vitesse de transition, l’intensité des fils, et la graine qui a déterminé la zone de départ (voir la page d’aide pour l’explication de ces éléments).
Le nom du fichier devient ainsi un journal d’exploration complet : il suffit de recopier les valeurs qu’il contient dans l’application, avec la même image d’origine, pour retrouver la composition à l’identique. N’importe qui peut donc reprendre une de mes images, en repartir, et la pousser dans une direction différente.
Une fois Zigbee2MQTT installé, la question devient concrète : comment ajouter des appareils et construire un maillage fiable dans toute la maison ? Je voulais par exemple ajouter des détecteurs d’ouverture de porte dans le garage. Mais les murs sont trop épais et ils ne se connectaient pas au dongle Zigbee. Voici la procédure pour raccorder une prise connectée et étendre le réseau sur plusieurs pièces. On y voit aussi comment installer un détecteur d’ouverture.
Cet article fait partie de la série Domotique Home Assistant.
Appairer une prise connectée comme répéteur
Les prises connectées Zigbee (ici une Nous A7Z) sont souvent vendues avec une application propriétaire, Tuya ou Nous Smart Home. Mieux vaut l’éviter et connecter la prise directement au réseau Zigbee local via Zigbee2MQTT, déjà installé. Trois avantages : la prise réagit plus vite, sans passer par un serveur distant, tes données restent chez toi, et surtout, une prise branchée sur secteur devient automatiquement un répéteur (routeur) qui agrandit ton maillage Zigbee.
1. Préparer la prise
Branche la prise sur une prise murale et observe le voyant LED sur le bouton latéral :
S’il clignote (lentement ou rapidement) : la prise est déjà en mode appairage.
S’il reste fixe : maintiens le bouton physique enfoncé pendant 5 à 7 secondes. La LED se met à clignoter rapidement, signe que les paramètres d’usine sont réinitialisés et que la prise cherche un réseau.
2. Lancer l’appairage dans Zigbee2MQTT
Ouvre l’interface web de Zigbee2MQTT et clique sur « Permit join » (Autoriser l’appairage), en bas du panneau latéral gauche.
Laisse la prise et Home Assistant communiquer, moins de 30 secondes suffisent. La LED de la prise s’arrête de clignoter et s’éteint. Un nouvel appareil apparaît dans la liste, identifié par défaut sous un nom générique du type « smart zigbee socket ».
Pas besoin de modifier quoi que ce soit à ce stade.
3. Renommer l’appareil
Toujours dans Zigbee2MQTT, ouvre la liste des appareils, clique sur la prise, puis modifie son nom. Donne-lui immédiatement un nom clair et localisé, par exemple « Prise Bureau (entrée) ». Si tu es sur Zigbee2MQTT, coche la case « Mettre à jour l’ID d’entité Home Assistant » pour que les entités soient renommées proprement partout, y compris côté Home Assistant.
Les entités disponibles après l’intégration
Une fois associée, la prise fait remonter automatiquement plusieurs informations dans tes tableaux de bord :
Le commutateur (switch) : pour allumer ou éteindre l’appareil branché, à distance.
La puissance instantanée (sensor.power, en watts) : utile pour voir ce que consomme un appareil en temps réel, ou créer des automatisations, par exemple une alerte quand la machine à laver tombe à 2 W, signe que le cycle est terminé.
La consommation cumulée (sensor.energy, en kWh) : l’entité à intégrer dans l’onglet Énergie de Home Assistant pour suivre tes coûts électriques.
Une fois les appareils appairés, ils apparaissent automatiquement dans l’aperçu de Home Assistant. Dès que tu leur assignes une pièce, ils s’affichent aussi dans l’aperçu de cet espace.
Conseil pour le réseau : comme la prise est branchée sur secteur, elle fait office de routeur. Laisse passer 24 à 48 heures sans la débrancher, le temps que tes autres capteurs sur pile (boutons, thermomètres) se maillent intelligemment à elle si besoin.
Ajouter un détecteur d’ouverture porte ou fenêtre
Les détecteurs Aqara MCCGQ11LM se composent de deux parties : un grand boîtier (le capteur principal) et un petit boîtier (l’aimant). Ils fonctionnent avec une pile bouton CR1632.
Appairage
La procédure suit le même principe que pour la prise, dans Zigbee2MQTT puis Home Assistant :
Repère le petit bouton physique sur une des tranches du grand boîtier.
Reste appuyé dessus pendant environ 5 secondes, jusqu’à ce que la petite LED bleue en façade clignote, puis relâche.
Pendant que Zigbee2MQTT cherche le capteur, appuie brièvement sur ce même bouton toutes les 2 à 3 secondes, pour forcer le capteur à rester éveillé jusqu’à ce que l’association soit complète. C’est une particularité des capteurs Aqara.
Une fois associé, tu dois voir le capteur passer en mode « ouvert » lorsque tu approches le petit boîtier du grand, et inversement en mode « fermé » quand tu les éloignes.
Installation physique
Le grand boîtier se colle sur la partie fixe (le cadre de la porte ou de la fenêtre), le petit aimant sur la partie mobile (le battant). Deux points d’attention :
Une fois la porte fermée, l’écart entre les deux boîtiers ne doit pas dépasser 22 mm.
Les petits repères (une ligne fine gravée sur le côté de chaque boîtier) doivent être alignés l’un en face de l’autre.
Astuce pour le positionnement : une carte bancaire standard fait 0,76 mm d’épaisseur. Deux cartes empilées donnent une cale pratique pour espacer correctement les deux boîtiers avant de les coller définitivement.
Étendre le maillage à plusieurs prises
Ajouter une deuxième ou une troisième prise pose une question classique : faut-il les appairer directement à leur emplacement final, ou peut-on les appairer près du dongle Zigbee pour simplifier la manipulation, puis les déplacer ensuite ?
Pourquoi l’appairage à proximité fonctionne
Le protocole Zigbee forme un réseau maillé (mesh) et dynamique. Lors de l’appairage, l’appareil a seulement besoin de s’enregistrer auprès du coordinateur, ton dongle USB, et d’y enregistrer sa clé de sécurité. Peu importe qu’il passe directement par le dongle ou par un relais à ce moment précis.
La règle d’or après le déplacement : le temps de « guérison »
Si tu appaires une prise destinée au garage dans ton bureau, elle crée d’abord un lien direct avec le dongle. Quand tu la débranches pour l’installer définitivement dans le garage, Home Assistant la voit d’abord « hors ligne » : elle cherche son ancien voisin (le dongle du bureau) et ne le trouve plus.
C’est là que le maillage entre en jeu : la prise émet un signal pour chercher de nouveaux voisins, détecte une autre prise déjà en place à proximité, et se reconnecte au réseau à travers elle. Ce processus de reconfiguration automatique s’appelle la « guérison » (healing) du réseau.
Ce processus n’est pas instantané, il peut prendre entre 10 minutes et un gros quart d’heure. Pas d’inquiétude si l’appareil reste indisponible juste après l’avoir branché à son emplacement définitif.
Méthode recommandée pour plusieurs prises
Pour enchaîner l’ajout de plusieurs prises sans perturber le réseau, suis cet ordre :
Appairer la prise 2 (par exemple, salon) dans le bureau : lance le mode inclusion dans Zigbee2MQTT, branche la prise à proximité, appaire-la et renomme-la.
Placer la prise 2 à son emplacement définitif : débranche-la du bureau et branche-la au salon. Attends 5 à 10 minutes qu’elle se reconnecte au dongle ou à la première prise et se stabilise.
Appairer la prise 3 (par exemple, garage) dans le bureau, pendant que la prise 2 se stabilise ailleurs.
Placer la prise 3 à son emplacement définitif : comme la prise du salon est déjà en place et active, la prise du garage trouvera ce relais plus facilement pour stabiliser son signal.
Vérifier son maillage : LQI et carte réseau
Le LQI, pour Link Quality Indicator (indice de qualité du lien), mesure la force et la fiabilité de la communication entre un appareil Zigbee et son contrôleur ou son routeur. Tu le retrouves directement dans la fiche de chaque appareil sur Zigbee2MQTT.
Un mur en parpaing plein rempli de galets concassés, par exemple, dégrade sensiblement le signal, un peu comme pour le Wi-Fi. Un LQI plus faible sur un appareil isolé dans une pièce éloignée n’est donc pas anormal.
Utiliser la carte Zigbee
Une fois tous les appareils branchés à leur place définitive, attends environ 30 minutes, puis va sur l’interface de Zigbee2MQTT, dans l’onglet Réseau :
Dans le menu déroulant Type d’affichage, choisir « afficher données / carte »
Dans le menu déroulant à droite « Type d’affichage« , choisir « carte »
Clique sur le bouton bleu Charger.
Le chargement prend quelques instants. Tu verras ensuite apparaître les lignes qui relient tes appareils entre eux, preuve visuelle que le maillage fonctionne. On voit que des liens se créent entre éléments. Un des capteurs d’ouverture est relié par l’intermédiaire de la prise A du bureau, l’autre en direct vers le « coordinateur » jaune, le dongle Zigbee de l’ordinateur Home Assistant.
Pour aller plus loin
Cet article fait partie de la série Domotique Home Assistant, qui regroupe les projets domotique créé dans Home Assistant. Je prévois d’y ajouter rapidement un article sur la façon de suivre les consommations d’énergie, avec une connexion quotidienne au site Enedis pour récupérer mes consommations quotidienne. Et un peu après, je voudrais créer un petit système d’alarme qui s’actionne quand des portes sont ouvertes en l’absence de certains téléphones « validés ».
Ce POC trie les pixels d’une image par couleur, comme l’application Attracteurs étranges déformait une image en suivant la trajectoire d’un attracteur mathématique. Mais l’important ici n’est pas l’application. C’est l’environnement, minimal, et la méthode pour construire ce genre de projet avec l’IA, même sans bagage en code.
Le principe du POC
Un fichier HTML unique, sans dépendance externe. Il charge une image, la lit pixel par pixel dans un canvas caché, trie ces pixels par teinte puis par luminosité, et affiche le résultat à côté de l’image d’origine. Tout se passe dans le navigateur, aucune image n’est envoyée à un serveur.
C’est volontairement un projet minimal, pas une application finie. Le but est de montrer qu’on peut obtenir un résultat fonctionnel, rapide et sécurisé, en une poignée d’échanges avec l’IA.
Ci-dessous sur un écran en mode portrait :
ou en mode paysage, avec une autre image
Le cahier des charges avant de coder
Avant d’écrire la moindre ligne de code, la première chose à faire est de poser un cahier des charges, même court. Trois questions suffisent pour ce genre de petit projet :
Que doit faire l’application, précisément ?
Quelles contraintes techniques et de sécurité s’appliquent (aucune donnée envoyée au serveur, un seul fichier autonome) ?
Sur quels supports doit-elle fonctionner (ordinateur, téléphone) ?
Ce dernier point vient d’une leçon apprise sur le projet Attracteurs : l’adaptation au téléphone n’avait pas été anticipée dans le cahier des charges initial, et n’a été détectée qu’en testant sur téléphone après coup. Pour ce projet, la contrainte responsive a été posée dès le départ.
Autre principe utile : ne pas réinventer ce qui existe déjà. Le chargement sécurisé d’image et la lecture des pixels via un canvas caché avaient déjà été validés sur le projet Attracteurs. Il n’y avait aucune raison de repartir de zéro sur ce point, seule la logique de tri était vraiment nouvelle.
Discuter avec l’IA pour jauger la complexité
Une fois le tri de base posé, une idée est venue en cours de route : permettre de survoler l’image triée à la souris pour afficher la couleur du pixel pointé, en RGB et en HSL. Une bonne question à se poser à ce moment-là : est-ce simple à ajouter, ou est-ce que ça mérite d’être traité à part ?
La réponse, discutée avec l’IA, a été de séparer le projet en deux étapes. L’étape A, le tri lui-même, suffisante pour valider le principe. L’étape B, le survol interactif, repoussée à une session suivante. Deux raisons à ce choix : tester une chose à la fois évite de devoir déboguer plusieurs nouveautés en même temps, et une fonctionnalité tactile (le survol au doigt pose des questions différentes de la souris) mérite sa propre réflexion plutôt que d’être ajoutée dans la précipitation.
C’est ce genre d’arbitrage qui fait la différence entre un prompt unique qui tente de tout faire d’un coup, et une conversation qui avance par étapes validées.
Le code complet
<!DOCTYPE html>
<html lang="fr">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>Tri de pixels par couleur</title>
<style>
:root {
--bg: #0b0d12;
--panel: rgba(20, 22, 30, 0.9);
--line: rgba(255, 255, 255, 0.10);
--txt: #e4e5ea;
--dim: #9497a3;
--accent: #2979ff;
}
* { box-sizing: border-box; margin: 0; padding: 0; }
[hidden] { display: none !important; }
body {
background: var(--bg);
color: var(--txt);
font-family: "Segoe UI", system-ui, -apple-system, sans-serif;
font-size: 14px;
padding: 16px;
min-height: 100vh;
}
h1 {
font-size: 15px;
font-weight: 600;
letter-spacing: 0.06em;
text-transform: uppercase;
color: var(--dim);
margin-bottom: 14px;
}
h1 b { color: var(--accent); font-weight: 600; }
#panel {
background: var(--panel);
border: 1px solid var(--line);
border-radius: 10px;
padding: 14px;
margin-bottom: 16px;
display: flex;
align-items: center;
gap: 12px;
flex-wrap: wrap;
}
input[type=file] { color: var(--dim); max-width: 100%; }
.btn {
padding: 8px 14px;
border: 1px solid var(--line);
border-radius: 7px;
background: rgba(255,255,255,0.06);
color: var(--txt);
font-size: 13px;
cursor: pointer;
}
.btn:hover { border-color: var(--accent); }
#status {
color: var(--dim);
font-size: 13px;
}
#resultats {
display: flex;
gap: 16px;
flex-wrap: wrap;
}
figure {
flex: 1 1 380px;
min-width: 0;
background: var(--panel);
border: 1px solid var(--line);
border-radius: 10px;
padding: 12px;
}
figure canvas {
display: block;
width: 100%;
height: auto;
border-radius: 6px;
background: #000;
}
figcaption {
color: var(--dim);
font-size: 12px;
text-transform: uppercase;
letter-spacing: 0.06em;
margin-bottom: 8px;
}
@media (max-width: 820px) {
#resultats { flex-direction: column; }
}
</style>
</head>
<body>
<h1>Tri de pixels par <b>couleur</b></h1>
<div id="panel">
<input type="file" id="file" accept="image/*">
<button type="button" class="btn" id="demo" hidden>Image de démonstration</button>
<span id="status">Choisis une image pour commencer.</span>
</div>
<div id="resultats" hidden>
<figure>
<figcaption>Image d'origine</figcaption>
<canvas id="cvOriginal"></canvas>
</figure>
<figure>
<figcaption>Pixels triés par teinte, puis luminosité</figcaption>
<canvas id="cvTrie"></canvas>
</figure>
</div>
<script>
const ui = {
file: document.getElementById("file"),
demo: document.getElementById("demo"),
status: document.getElementById("status"),
resultats: document.getElementById("resultats"),
cvOriginal: document.getElementById("cvOriginal"),
cvTrie: document.getElementById("cvTrie"),
};
const TAILLE_MAX = 1200; // plus grande dimension autorisée pour la taille de travail
const DEMO_DIR = "demo/";
/* ============================================================
Chargement d'une image choisie par l'utilisateur
============================================================ */
ui.file.addEventListener("change", () => {
const f = ui.file.files && ui.file.files[0];
if (!f) return;
const url = URL.createObjectURL(f);
const img = new Image();
img.onload = () => {
URL.revokeObjectURL(url);
traiterImage(img);
};
img.onerror = () => {
URL.revokeObjectURL(url);
ui.status.textContent = "Impossible de lire ce fichier image.";
};
img.src = url;
});
/* ============================================================
Images de démonstration
Le manifeste n'est lu que si l'application est servie en
http(s). En ouverture directe du fichier (file://), l'appel
échoue silencieusement et le bouton reste caché : rien ne
bloque, l'utilisateur charge simplement sa propre image.
============================================================ */
let demoListe = [];
fetch(DEMO_DIR + "manifest.json")
.then(r => r.ok ? r.json() : [])
.then(liste => {
if (Array.isArray(liste) && liste.length) {
demoListe = liste;
ui.demo.hidden = false;
}
})
.catch(() => {});
ui.demo.addEventListener("click", () => {
if (!demoListe.length) return;
const nom = demoListe[Math.floor(Math.random() * demoListe.length)];
const img = new Image();
img.onload = () => traiterImage(img);
img.onerror = () => { ui.status.textContent = "Impossible de charger l'image de démonstration."; };
img.src = DEMO_DIR + nom;
});
/* ============================================================
Redimensionnement interne
La plus grande dimension de l'image est ramenée à TAILLE_MAX
si besoin, pour garder le tri fluide sur tous les appareils.
Le rapport largeur/hauteur d'origine est conservé.
============================================================ */
function calculerTailleTravail(largeur, hauteur) {
const plusGrand = Math.max(largeur, hauteur);
if (plusGrand <= TAILLE_MAX) return { w: largeur, h: hauteur };
const ratio = TAILLE_MAX / plusGrand;
return {
w: Math.max(1, Math.round(largeur * ratio)),
h: Math.max(1, Math.round(hauteur * ratio)),
};
}
/* ============================================================
Conversion RGB vers HSL
Seules la teinte (h, 0-360) et la luminosité (l, 0-1) sont
utilisées ici comme critères de tri.
============================================================ */
function rgbVersHsl(r, g, b) {
r /= 255; g /= 255; b /= 255;
const max = Math.max(r, g, b), min = Math.min(r, g, b);
const l = (max + min) / 2;
if (max === min) return { h: 0, l };
const d = max - min;
let h;
switch (max) {
case r: h = ((g - b) / d + (g < b ? 6 : 0)); break;
case g: h = ((b - r) / d + 2); break;
default: h = ((r - g) / d + 4);
}
h *= 60;
return { h, l };
}
/* ============================================================
Traitement principal : lecture, tri, reconstruction, affichage
============================================================ */
function traiterImage(img) {
ui.status.textContent = "Traitement en cours...";
ui.resultats.hidden = true;
// laisse le navigateur afficher le message de statut avant
// de démarrer le calcul, potentiellement bloquant
requestAnimationFrame(() => {
const { w, h } = calculerTailleTravail(img.naturalWidth, img.naturalHeight);
const n = w * h;
// canvas caché pour la lecture des pixels, image redimensionnée
const cvLecture = document.createElement("canvas");
cvLecture.width = w;
cvLecture.height = h;
const ctxLecture = cvLecture.getContext("2d", { willReadFrequently: true });
ctxLecture.drawImage(img, 0, 0, w, h);
const donnees = ctxLecture.getImageData(0, 0, w, h).data;
// teinte et luminosité de chaque pixel, calculées une seule fois
const teintes = new Float32Array(n);
const luminosites = new Float32Array(n);
for (let i = 0; i < n; i++) {
const j = i * 4;
const { h: teinte, l } = rgbVersHsl(donnees[j], donnees[j + 1], donnees[j + 2]);
teintes[i] = teinte;
luminosites[i] = l;
}
// indices des pixels triés par teinte, puis par luminosité
const indices = new Uint32Array(n);
for (let i = 0; i < n; i++) indices[i] = i;
const indicesTries = Array.from(indices).sort((a, b) => {
if (teintes[a] !== teintes[b]) return teintes[a] - teintes[b];
return luminosites[a] - luminosites[b];
});
// reconstruction de l'image triée : les pixels triés sont replacés
// dans l'ordre de lecture habituel (ligne par ligne), en gardant
// leur couleur exacte d'origine
const imageTrie = ctxLecture.createImageData(w, h);
const sortie = imageTrie.data;
for (let i = 0; i < n; i++) {
const source = indicesTries[i] * 4;
const cible = i * 4;
sortie[cible] = donnees[source];
sortie[cible + 1] = donnees[source + 1];
sortie[cible + 2] = donnees[source + 2];
sortie[cible + 3] = donnees[source + 3];
}
// affichage : image d'origine
ui.cvOriginal.width = w;
ui.cvOriginal.height = h;
ui.cvOriginal.getContext("2d").drawImage(img, 0, 0, w, h);
// affichage : image triée
ui.cvTrie.width = w;
ui.cvTrie.height = h;
ui.cvTrie.getContext("2d").putImageData(imageTrie, 0, 0);
ui.resultats.hidden = false;
ui.status.textContent = `Image traitée : ${w} x ${h} px (${n.toLocaleString("fr-FR")} pixels).`;
});
}
</script>
</body>
</html>
Pour les images de démonstration, un dossier demo/ contient un fichier manifest.json listant simplement leurs noms :
json
["falaise.jpg", "port-breton.png"]
S’il est absent, rien ne bloque, le bouton « Image de démonstration » reste caché et le visiteur charge sa propre image.
Tester en local, sans rien connaître
Trois façons de servir ce fichier avant de le mettre en ligne, du plus accessible au plus technique.
La solution VSCodium, ou VSCode (non testée), avec l’extension Live Server, est la plus simple si tu ne veux rien installer d’autre qu’un éditeur de code. Un clic droit sur le fichier HTML, « Open with Live Server », et la page s’ouvre dans le navigateur avec rechargement automatique à chaque modification.
Un serveur Python local, sur une machine où Python est déjà installé. Dans le dossier contenant le fichier :
python3 -m http.server 8000
Puis ouvrir http://localhost:8000/tri-pixels-couleur.html dans le navigateur. Si le serveur tourne sur une autre machine du même réseau local (un boîtier Linux par exemple), remplacer localhost par l’adresse IP locale de cette machine, du type http://192.168.x.x:8000/tri-pixels-couleur.html.
Sous Windows, la même commande peut nécessiter d’installer Python au préalable (depuis python.org, pas le Microsoft Store), cette option n’a pas été testée dans le cadre de ce projet.
Mettre en ligne, gratuitement
J’ai testé et validé deux options pour ce projet.
option Page Github
GitHub Pages, pour un partage public et gratuit, indépendant de tout hébergement personnel :
Créer un compte GitHub si besoin (github.com, gratuit)
Créer un dépôt public, par exemple tri-pixels-couleur, sans rien cocher (pas de README, pas de licence)
Dans le dépôt, « Add file » puis « Upload files », déposer le fichier HTML renommé en index.html, et si besoin le dossier demo/ avec son manifeste et ses images
Dans « Settings » puis « Pages », section « Build and deployment », choisir « Deploy from a branch », branche main, dossier / (root)
L’URL publique apparaît en haut de cette même page après une à deux minutes, du type https://ton-pseudo.github.io/tri-pixels-couleur/.
Un sous-répertoire de son propre site, avec un vrai hébergement web. Même principe que l’application Attracteurs étranges : déposer le fichier HTML renommé en index.html dans un dossier dédié à la racine du site (via FTP ou le gestionnaire de fichiers de l’hébergeur), avec le dossier demo/ à côté si besoin. L’URL devient propre automatiquement, sans conflit avec les permaliens WordPress. Pour l’application Attracteurs étranges, ça fonctionne parfaitement ici : https://knowledge.parcours-performance.com/attracteurs/
C’est quoi le vibe coding ?
Le terme désigne une façon de coder en dialoguant avec une IA en langage naturel, plutôt qu’en écrivant soi-même chaque ligne. On décrit ce qu’on veut, l’IA propose du code, on teste, on ajuste, on recommence.
Ce projet en est un exemple assez pur : aucune ligne de ce fichier n’a été tapée à la main, tout est passé par une conversation structurée, cahier des charges d’abord, questions une par une, validation avant chaque étape de code.
C’est aussi une bonne méthode pour construire un POC (proof of concept, ou preuve de concept en français. On pourrait aussi dire prototype), c’est-à-dire une version minimale d’une idée, juste assez fonctionnelle pour vérifier qu’elle tient debout, avant d’envisager d’aller plus loin. Cette expérimentation en est un exemple : elle ne visait pas à produire un outil fini, seulement à valider rapidement plusieurs options sécurisées pour mettre en ligne des applications en html et javascript.
Ce principe s’applique à beaucoup d’autres petits projets, créatifs ou utiles. Quelques idées pour continuer à s’entraîner :
Un générateur de palette de couleurs à partir d’une photo
Une page de calcul simple pour une TPE, devis, marge, conversion d’unités
Un petit générateur de mots de passe ou de QR codes, entièrement local
Une visualisation ludique de données personnelles, dépenses, lectures, trajets
Cet article fait partie de la série des articles sur la création d’une IA locale dans mon bureau : Créer une IA locale.
Anonymiser un document, c’est supprimer définitivement les données personnelles qu’il contient. Pseudonymiser, c’est différent : tu remplaces temporairement ces données par un identifiant neutre, tu traites le document sans jamais voir l’information sensible, puis tu réinjectes les vraies données à la fin. Voici comment tester ce principe chez toi, sur un PC modeste, avec des outils open source.
Le principe en 3 étapes
Détecter les données personnelles dans un texte et les remplacer par un jeton neutre (par exemple PERSONNE_1 à la place d’un prénom).
Traiter le texte anonymisé avec une intelligence artificielle, qui ne voit jamais l’identité réelle de la personne.
Réinjecter l’information réelle à la place du jeton dans le résultat final.
L’intérêt : le traitement (recherche, analyse, génération de contenu) se fait sans exposer l’identité de la personne concernée, ce qui limite les risques si le document venait à être mal utilisé ou transmis à un tiers.
Les outils utilisés
Presidio, un outil open source de Microsoft, pour détecter les données personnelles dans le texte (reconnaissance d’entités nommées).
spaCy, une bibliothèque de traitement du langage, utilisée par Presidio pour comprendre le texte en français.
Ollama avec le modèle qwen2.5:3b, pour le traitement IA local, sans aucune donnée envoyée sur internet.
Tout tourne en local sur un Mini PC Linux, sans connexion à un service externe.
Installer l’environnement
Le script tourne dans un environnement Python isolé (un venv), séparé du reste du système. Ça évite que les bibliothèques installées pour ce projet entrent en conflit avec d’autres outils déjà présents sur la machine.
Crée le dossier du projet et vérifie que le paquet nécessaire à la création d’un venv est installé :
mkdir -p ~/docker/pseudonymisation
cd ~/docker/pseudonymisation
dpkg -l | grep python3-venv
Si la commande ne retourne rien, installe le paquet (le numéro de version dépend de ta machine, la commande d’installation exacte apparaît dans le message d’erreur si tu tentes de créer le venv directement) :
sudo apt update
sudo apt upgrade
sudo reboot
Après le redémarrage, reconnecte-toi en SSH et installe le paquet indiqué par le message d’erreur, par exemple :
sudo apt install python3.12-venv
Crée ensuite le venv, sans sudo (une commande avec sudo donnerait les droits root aux fichiers créés, ce qui complique ensuite toute modification) :
cd ~/docker/pseudonymisation
python3 -m venv venv
source venv/bin/activate
La ligne de commande affiche maintenant (venv) au début, signe que l’environnement isolé est actif. Installe les bibliothèques nécessaires et le modèle de langue française :
Le modèle fr_core_news_sm est le plus léger disponible pour le français. Sur un PC peu puissant et pour un test avec des textes courts, il est peut-être suffisant. Un modèle plus complet (fr_core_news_md) existe si la détection s’avère insuffisante.
Enregistre la liste des bibliothèques installées, pour pouvoir tout réinstaller à l’identique en cas de besoin :
pip freeze > requirements.txt
Vérifier que la détection fonctionne
Avant de construire le script complet, un test simple permet de vérifier que Presidio détecte bien un prénom dans une phrase.
Crée le fichier test_detection.py :
from presidio_analyzer import AnalyzerEngine
from presidio_analyzer.nlp_engine import NlpEngineProvider
configuration = {
"nlp_engine_name": "spacy",
"models": [{"lang_code": "fr", "model_name": "fr_core_news_sm"}]
}
provider = NlpEngineProvider(nlp_configuration=configuration)
nlp_engine = provider.create_engine()
analyzer = AnalyzerEngine(nlp_engine=nlp_engine, supported_languages=["fr"])
texte_origine = "Bonjour, je m'appelle Pierre Durand et j'habite à Paris."
resultats = analyzer.analyze(text=texte_origine, language="fr")
for res in resultats:
print(f"Trouvé: {texte_origine[res.start:res.end]} -> Catégorie: {res.entity_type}")
Lance-le :
python test_detection.py
Résultat obtenu :
Trouvé: Pierre Durand -> Catégorie: PERSON
Trouvé: Paris -> Catégorie: LOCATION
La détection fonctionne, on peut construire le script complet.
Créer des documents de test
Pour tester le workflow, j’ai créé 5 courts textes fictifs, chacun avec un prénom, un âge et un animal préféré, rédigés comme des présentations naturelles plutôt que des formulaires. Crée un dossier documents/ et un fichier par personne :
mkdir -p ~/docker/pseudonymisation/documents
cat > ~/docker/pseudonymisation/documents/personne1.txt << 'EOF'
Bonjour, je m'appelle Léa et j'ai 34 ans. Je travaille dans une pépinière depuis quelques années. Si je devais choisir un animal préféré, ce serait sans hésiter l'axolotl, je trouve sa capacité à régénérer ses membres absolument fascinante.
EOF
cat > ~/docker/pseudonymisation/documents/personne2.txt << 'EOF'
Je me présente, je suis Thomas, j'ai 52 ans et je vis à la campagne. Mon animal préféré est le fennec, ses grandes oreilles et son adaptation au désert m'ont toujours impressionné depuis un documentaire vu il y a longtemps.
EOF
cat > ~/docker/pseudonymisation/documents/personne3.txt << 'EOF'
Salut, moi c'est Camille, 27 ans. J'adore les animaux un peu décalés, et mon préféré reste le quokka, ce petit marsupial australien qui semble toujours sourire sur les photos.
EOF
cat > ~/docker/pseudonymisation/documents/personne4.txt << 'EOF'
Je m'appelle Julien et j'ai 45 ans. Passionné de nature depuis l'enfance, mon animal préféré est le pangolin, une créature discrète et méconnue que je trouve pourtant étonnante avec ses écailles.
EOF
cat > ~/docker/pseudonymisation/documents/personne5.txt << 'EOF'
Bonjour, je suis Sophie, j'ai 61 ans et je suis récemment partie à la retraite. Mon animal préféré est l'okapi, cet étrange cousin de la girafe que j'ai découvert lors d'un voyage il y a quelques années.
EOF
Le script d’anonymisation
Ce script lit chaque fichier, détecte les entités présentes (pas seulement le prénom, pour observer aussi ce que Presidio détecte d’autre), les remplace par des jetons, et sauvegarde la correspondance dans un fichier JSON.
Crée anonymisation.py :
import os
import json
from presidio_analyzer import AnalyzerEngine
from presidio_analyzer.nlp_engine import NlpEngineProvider
DOSSIER_SOURCE = "documents"
DOSSIER_ANONYMISE = "documents_anonymises"
DOSSIER_RECONSTRUIT = "documents_reconstruits"
FICHIER_CORRESPONDANCE = "correspondance.json"
configuration = {
"nlp_engine_name": "spacy",
"models": [{"lang_code": "fr", "model_name": "fr_core_news_sm"}]
}
provider = NlpEngineProvider(nlp_configuration=configuration)
nlp_engine = provider.create_engine()
analyzer = AnalyzerEngine(nlp_engine=nlp_engine, supported_languages=["fr"])
os.makedirs(DOSSIER_ANONYMISE, exist_ok=True)
os.makedirs(DOSSIER_RECONSTRUIT, exist_ok=True)
correspondance_globale = {}
for nom_fichier in sorted(os.listdir(DOSSIER_SOURCE)):
if not nom_fichier.endswith(".txt"):
continue
chemin_source = os.path.join(DOSSIER_SOURCE, nom_fichier)
with open(chemin_source, "r", encoding="utf-8") as f:
texte = f.read()
resultats = analyzer.analyze(text=texte, language="fr")
resultats_tries = sorted(resultats, key=lambda r: r.start, reverse=True)
correspondance_fichier = {"prenom": None, "autres_elements_personnels": []}
texte_anonymise = texte
compteur_autres = 0
prenom_trouve = False
for res in resultats_tries:
valeur = texte[res.start:res.end]
if res.entity_type == "PERSON" and not prenom_trouve:
jeton = "PERSONNE_1"
correspondance_fichier["prenom"] = {"jeton": jeton, "valeur": valeur}
prenom_trouve = True
else:
compteur_autres += 1
jeton = f"AUTRE_{compteur_autres}"
correspondance_fichier["autres_elements_personnels"].append(
{"jeton": jeton, "valeur": valeur, "categorie": res.entity_type}
)
texte_anonymise = texte_anonymise[:res.start] + jeton + texte_anonymise[res.end:]
with open(os.path.join(DOSSIER_ANONYMISE, nom_fichier), "w", encoding="utf-8") as f:
f.write(texte_anonymise)
correspondance_globale[nom_fichier] = correspondance_fichier
texte_reconstruit = texte_anonymise
if correspondance_fichier["prenom"]:
texte_reconstruit = texte_reconstruit.replace(
correspondance_fichier["prenom"]["jeton"],
"[ " + correspondance_fichier["prenom"]["valeur"] + " ]"
)
if correspondance_fichier["autres_elements_personnels"]:
texte_reconstruit += "\n\nAutres elements personnels detectes :\n"
for item in correspondance_fichier["autres_elements_personnels"]:
texte_reconstruit += f"- {item['jeton']} : {item['valeur']} ({item['categorie']})\n"
with open(os.path.join(DOSSIER_RECONSTRUIT, nom_fichier), "w", encoding="utf-8") as f:
f.write(texte_reconstruit)
with open(FICHIER_CORRESPONDANCE, "w", encoding="utf-8") as f:
json.dump(correspondance_globale, f, ensure_ascii=False, indent=2)
print("Termine. Verifie documents_anonymises/, documents_reconstruits/ et correspondance.json")
Lance le script :
python anonymisation.py
Le dossier documents_reconstruits/ sert de test intermédiaire : il réinjecte immédiatement le prénom entre crochets ([ Léa ]) pour vérifier visuellement que le mécanisme fonctionne, avant même d’ajouter le traitement IA.
Sur les 5 documents testés, la détection a globalement bien fonctionné, avec deux limites observées :
sur personne1.txt, Presidio n’a détecté aucune entité, y compris le prénom Léa pourtant présent en clair. Le modèle léger fr_core_news_sm peut manquer certains prénoms.
sur personne3.txt, le mot « Salut » a été classé comme un lieu (LOCATION), un faux positif.
Ces limites sont attendues avec un modèle allégé et font partie de ce qu’on cherche à observer dans ce test.
Le traitement par IA
Le texte anonymisé est envoyé à qwen2.5:3b via Ollama, avec une consigne qui demande à la fois l’animal préféré et un signalement de toute donnée personnelle restante dans le texte, une façon de vérifier si l’IA repère les éventuels oublis de l’étape précédente.
Un test sur un seul fichier permet de vérifier le format de réponse avant de généraliser :
import requests
with open("documents_anonymises/personne2.txt", "r", encoding="utf-8") as f:
texte_anonymise = f.read()
prompt = f"""Voici un texte. Reponds uniquement avec ce format exact, sans phrase supplementaire :
Animal prefere : [ton animal trouve]
Attention - donnees personnelles : [liste les elements qui sont des donnees personnelles, ou ecris "aucun"]
Texte : {texte_anonymise}"""
reponse = requests.post(
"http://localhost:11434/api/generate",
json={"model": "qwen2.5:3b", "prompt": prompt, "stream": False}
)
print(reponse.json()["response"])
Une fois le format validé, le script complet traite les 5 documents :
import os
import json
import requests
DOSSIER_ANONYMISE = "documents_anonymises"
FICHIER_RESULTATS = "resultats_ia.json"
resultats = {}
for nom_fichier in sorted(os.listdir(DOSSIER_ANONYMISE)):
if not nom_fichier.endswith(".txt"):
continue
chemin = os.path.join(DOSSIER_ANONYMISE, nom_fichier)
with open(chemin, "r", encoding="utf-8") as f:
texte_anonymise = f.read()
prompt = f"""Voici un texte. Reponds uniquement avec ce format exact, sans phrase supplementaire :
Animal prefere : [ton animal trouve]
Attention - donnees personnelles : [liste les elements qui sont des donnees personnelles, ou ecris "aucun"]
Texte : {texte_anonymise}"""
reponse = requests.post(
"http://localhost:11434/api/generate",
json={"model": "qwen2.5:3b", "prompt": prompt, "stream": False}
)
resultats[nom_fichier] = reponse.json()["response"]
print(f"{nom_fichier} traite.")
with open(FICHIER_RESULTATS, "w", encoding="utf-8") as f:
json.dump(resultats, f, ensure_ascii=False, indent=2)
print("Termine. Verifie resultats_ia.json")
Sur plusieurs exécutions successives de ce script, un même document (personne5.txt) a systématiquement échoué à respecter le format demandé : au lieu de répondre selon la consigne, le modèle a recopié le texte source. Un autre document a échoué une fois sur trois essais, avant de fonctionner correctement. Ce comportement n’est pas lié au prompt (qui fonctionne pour la majorité des textes), plutôt à une limite connue des petits modèles sur le respect strict d’un format de sortie.
La réinjection finale
Le dernier script combine le prénom réel, l’animal trouvé par l’IA et les éventuelles autres données personnelles détectées, pour produire un document final par personne :
import os
import json
FICHIER_CORRESPONDANCE = "correspondance.json"
FICHIER_RESULTATS_IA = "resultats_ia.json"
DOSSIER_FINAL = "documents_finaux"
with open(FICHIER_CORRESPONDANCE, "r", encoding="utf-8") as f:
correspondance = json.load(f)
with open(FICHIER_RESULTATS_IA, "r", encoding="utf-8") as f:
resultats_ia = json.load(f)
os.makedirs(DOSSIER_FINAL, exist_ok=True)
for nom_fichier, corr in correspondance.items():
prenom = corr["prenom"]["valeur"] if corr["prenom"] else "PRENOM_NON_DETECTE"
reponse_ia = resultats_ia.get(nom_fichier, "")
animal = "non determine (echec du modele IA)"
for ligne in reponse_ia.splitlines():
if ligne.strip().lower().startswith("animal prefere"):
animal = ligne.split(":", 1)[1].strip()
break
contenu_final = f"Prenom : {prenom}\n"
contenu_final += f"Animal prefere : {animal}\n"
if corr["autres_elements_personnels"]:
contenu_final += "\nAutres elements personnels detectes :\n"
for item in corr["autres_elements_personnels"]:
contenu_final += f"- {item['jeton']} : {item['valeur']} ({item['categorie']})\n"
nom_sortie = nom_fichier.replace(".txt", "_final.txt")
with open(os.path.join(DOSSIER_FINAL, nom_sortie), "w", encoding="utf-8") as f:
f.write(contenu_final)
print("Termine. Verifie le dossier documents_finaux/")
Résultat obtenu sur les 5 documents :
Prenom : PRENOM_NON_DETECTE
Animal prefere : axolotl
Prenom : Thomas
Animal prefere : fennec
Prenom : Camille
Animal prefere : Quokka
Autres elements personnels detectes :
- AUTRE_1 : Salut (LOCATION)
Prenom : Julien
Animal prefere : pangolin
Prenom : Sophie
Animal prefere : non determine (echec du modele IA)
Chaque cas d’échec est signalé explicitement dans le document final, plutôt que masqué ou laissé vide, ce qui permet de voir immédiatement où le workflow a besoin d’être amélioré.
Ce qu’on a appris
Un PC ancien de bureautique suffit. Aucune lenteur notable, y compris pendant les 5 appels au modèle IA.
Le modèle spaCy léger a ses limites. Un prénom sur cinq n’a pas été détecté, et un faux positif est apparu sur un autre texte. Un modèle plus complet (fr_core_news_md) mériterait un test comparatif avant un usage réel.
Le petit modèle IA est inconstant sur le format. Un même texte peut réussir ou échouer à respecter la consigne selon l’essai. Une piste pour réduire cette variabilité, non testée ici : fixer le paramètre temperature à 0 dans la requête envoyée à Ollama.
Le principe fonctionne malgré ces limites. Le workflow complet, de la détection à la réinjection, tourne de bout en bout sans erreur bloquante, avec une gestion propre des cas d’échec.
Des cas d’usage possibles en entreprise
Ce principe dépasse largement le simple test avec des animaux préférés. Quelques exemples concrets :
Formulaires de contact ou de prospection : un prospect décrit son besoin, le texte est anonymisé avant d’être traité par une IA qui propose une base de réponse ou de devis, puis l’identité est réinjectée à la fin.
Formation : traiter des retours d’expérience ou des évaluations sans exposer l’identité des participants pendant l’analyse.
Plus largement, tout traitement IA sur des documents contenant des données sensibles, où l’on veut garder un contrôle strict sur qui voit quoi et à quel moment.
Open WebUI ne sait pas lire un PDF scanné : il faut une couche d’OCR. Tika, un service Apache open source, comble ce manque. Voici comment l’installer, le piège à éviter, et ce que ça change vraiment sur un Mini PC.
Cet article fait partie de deux séries :
la série des articles sur Linux et des logiciels installés en containers Docker : projets Ubuntu
la série des articles sur la création d’une IA locale dans mon bureau : Créer une IA locale
Pourquoi Tika
Si tu as suivi l’article sur le RAG dans Open WebUI, tu as déjà l’embedding configuré avec nomic-embed-text, et tu sais que les modèles texte uniquement comme qwen2.5:3b ne lisent que le texte extrait d’un PDF, jamais une image.
Le problème, c’est que rien ne distingue à l’œil un PDF texte natif d’un PDF scanné : seul le contenu diffère. Si tu déposes un PDF scanné sans précaution, Open WebUI l’indexe sans erreur visible, mais le document reste vide de tout texte utilisable. Le modèle répond alors qu’il ne trouve pas l’information, même si elle est sous ses yeux.
Tika résout ce problème : c’est un serveur qui extrait le texte de n’importe quel format de document, PDF compris, et qui sait appliquer une reconnaissance optique de caractères (OCR) quand le PDF est une image plutôt que du texte.
Étape 1 – Installer Tika via Portainer
Avant d’installer un nouveau container, vérifie les ports déjà utilisés :
Tika ne nécessite pas de volume : il traite les fichiers à la volée, sans rien conserver entre les requêtes. Si tu veux un jour personnaliser son comportement (désactiver l’OCR, ajuster sa résolution), cela se fait via un fichier de configuration séparé, mais ce n’est pas nécessaire pour un usage standard.
Crée quand même un répertoire dédié, pour garder une trace du paramétrage en cas de réinstallation sur une autre machine :
Le piège à éviter : l’image apache/tika existe en deux versions. Le tag latest correspond à une version minimale, sans aucune capacité d’OCR. Pour que Tika sache lire un PDF scanné, il faut impérativement le tag latest-full, qui inclut Tesseract OCR. Avec le tag latest seul, l’installation semble fonctionner (le container démarre, le port répond), mais l’extraction d’un PDF image renvoie systématiquement un résultat vide, sans message d’erreur explicite.
Dans Portainer : Stacks > Add stack, nomme-le tika, colle le contenu ci-dessus dans l’éditeur web, puis déploie.
Si le texte du document s’affiche dans le terminal, l’OCR fonctionne. Une sortie vide signale que l’image utilisée n’est pas la version -full.
Étape 2 – Connecter Tika à Open WebUI
Connecte-toi à Open WebUI avec un compte administrateur, puis va dans Panneau d’administration > Réglages > Documents.
Dans Moteur d’extraction de contenu, sélectionne Tika, puis renseigne l’adresse du serveur :
http://tika:9998
Le nom tika correspond au nom du container, résolu automatiquement puisque Tika et Open WebUI partagent le même réseau Docker (ollama_default). Enregistre.
Je n’ai pas testé ce qui se passe pour des documents déjà indexés avant ce changement de moteur : il est possible qu’une réindexation soit nécessaire pour qu’ils bénéficient de l’OCR rétroactivement. Si tu pars d’une base de connaissances neuve, la question ne se pose pas.
Étape 3 – Tester avec un vrai PDF scanné
Pour être certain qu’un PDF est une image et non du texte, essaie de sélectionner du texte avec la souris dans une visionneuse PDF : si rien ne se sélectionne, c’est un scan.
Test en base de connaissances. Dans Espace de travail > Connaissances, ouvre une base existante (ou crée-en une), et dépose le PDF scanné. L’indexation se déroule sans erreur visible. Pose ensuite une question dont la réponse se trouve uniquement dans ce document, à l’agent associé à la base. La réponse est correcte et cite le document.
Test en pièce jointe directe. Dans une conversation normale, joins le même PDF directement au message, sans passer par une base de connaissances. La réponse arrive, correcte également, mais avec un temps de traitement nettement plus long.
Les deux scénarios fonctionnent : l’objectif principal (PDF scanné joint directement dans le chat) est atteint, tout comme le repli (PDF scanné en base de connaissances).
Le verdict : ça marche, mais c’est lent
Sur un Mini PC (Intel i5, 16 Go de RAM) qui fait déjà tourner Home Assistant, Mosquitto, Zigbee2MQTT, Ollama et Open WebUI, l’OCR via Tika consomme des ressources que la machine n’a pas en réserve. Le résultat est juste, mais l’attente se fait sentir, surtout en pièce jointe directe dans le chat.
Ce n’est pas une limite de Tika : l’OCR est par nature gourmand en calcul, quel que soit l’outil utilisé. Sur un matériel plus généreux, ou avec un GPU dédié, le temps de traitement serait nettement réduit.
Dans mon cas, je préfère donc réserver Tika à un usage ponctuel (l’indexation d’un PDF scanné dans une base de connaissances, qui ne se fait qu’une fois), plutôt qu’à un usage répété en pièce jointe directe dans une conversation. Pour les PDF que je sais scannés, je passe en amont par un OCR dédié avec Stirling PDF, déjà installé sur le même Mini PC selon la procédure décrite dans Installer et régler Stirling PDF via Docker. Le PDF ressort avec une couche de texte intégrée, et Open WebUI le traite alors comme un PDF texte natif classique, sans solliciter Tika.
Pour aller plus loin
Cet article fait partie d’une série sur l’IA locale : Créer une IA locale et l’installation de logiciels en containers Docker sous Ubuntu : projets Ubuntu
Ollama et Open WebUI installés, modèles téléchargés – le chat fonctionne. Mais si tu veux interroger tes propres documents sans les envoyer sur un serveur externe, il faut aller un cran plus loin : configurer le RAG. Cet article fait partie de deux séries :
la série des articles sur Linux et des logiciels installés en containers Docker : projets Ubuntu
La série des articles sur la création d’une IA locale dans mon bureau : Créer une IA locale
C’est quoi le RAG ?
RAG est l’acronyme de « Retrieval-Augmented Generation » – en français, génération augmentée par récupération. L’idée est simple : plutôt que de demander au modèle de répondre uniquement à partir de ce qu’il a appris pendant son entraînement, on lui fournit des passages extraits de tes propres documents. Le modèle s’appuie sur ces passages pour construire sa réponse.
En pratique, ça change tout : tu peux créer un assistant qui connaît ta documentation interne, tes notes, tes rapports – et qui répond en citant ses sources. Et si c’est fait dans un système local, rien ne sort vers l’extérieur.
Le rôle de l’embedding
Pour que le RAG fonctionne, le système doit être capable de trouver rapidement les passages pertinents dans tes documents avant de les transmettre au modèle. C’est le rôle de l’embedding – qu’on pourrait traduire par vectorisation sémantique, même si ce terme n’est pas d’usage courant.
Un modèle d’embedding lit chaque paragraphe de tes documents et le convertit en une liste de coordonnées mathématiques – un vecteur. Deux paragraphes qui parlent du même sujet auront des coordonnées proches, même s’ils n’utilisent pas les mêmes mots. Quand tu poses une question, ta question est convertie de la même façon, et le système trouve en quelques millisecondes les paragraphes les plus proches.
Le LLM ne reçoit alors que ces quelques paragraphes pertinents – pas l’intégralité du document. Sur un CPU sans carte graphique dédiée, c’est ce qui rend le système utilisable : le modèle n’a que quelques lignes à lire pour formuler sa réponse.
Les modèles testés dans cet article : qwen2.5:3b comme LLM, nomic-embed-text comme modèle d’embedding
Étape 1 – Télécharger le modèle d’embedding
nomic-embed-text est un modèle léger (~270 Mo), rapide sur CPU, avec une fenêtre de contexte de 8192 tokens – ce qui permet de découper les documents en morceaux suffisamment grands pour conserver le sens.
nomic-embed-text doit apparaître dans la liste aux côtés de tes modèles LLM.
Étape 2 – Configurer l’embedding dans Open WebUI
Dans Open WebUI, connecte-toi avec ton compte administrateur, puis va dans Panneau d’administration > Réglages > Documents.
Dans la section Embedding :
Moteur de modèle d’embedding : sélectionne Ollama
Modèle d’embedding : saisis nomic-embed-text
Clique sur Enregistrer.
Open WebUI délègue désormais toute la vectorisation à Ollama. Les deux modèles – LLM et embedding – tournent sur le même moteur, sans duplication de ressources.
Étape 3 – Créer une base de connaissances
Une base de connaissances est un ensemble de documents indexés sur un thème donné. C’est l’équivalent local d’un Projet Claude ou d’un Gem Gemini – sans que rien ne sorte de ta machine.
Dans Open WebUI, va dans Espace de travail > Connaissances, puis crée une nouvelle base avec un nom explicite (par exemple « Réglementation formation » ou « Documentation projet X »).
Glisse-dépose tes fichiers PDF ou TXT dans la zone dédiée. Le CPU va s’activer quelques secondes – c’est nomic-embed-text qui indexe et vectorise les documents en arrière-plan. Une fois l’indexation terminée, la base est prête.
Quelques points à garder en tête :
Les modèles texte uniquement (qwen2.5:3b, llama3.1, mistral) ne peuvent pas traiter des images – seul le texte extrait des PDF est utilisable
Pour les très longs documents (plus de 50-100 pages), laisse le CPU terminer l’indexation avant d’en ajouter d’autres
Étape 4 – Créer un agent associé à la base
La base de connaissances seule ne fait rien – il faut lui associer un agent, c’est-à-dire un modèle configuré avec un comportement précis.
Dans Espace de travail > Modèles, clique sur Créer un modèle, puis :
Donne-lui un nom explicite (par exemple « Assistant formation »)
Modèle de base : sélectionne qwen2.5:3b
Dans la section Connaissances, associe la base créée à l’étape précédente
Rédige un system prompt
Le system prompt est crucial. Sans instruction claire, le modèle complète avec ses connaissances générales plutôt que de s’appuyer sur tes documents. Un exemple efficace :
« Tu es l’assistant de [ton rôle]. Tu réponds uniquement à partir des documents fournis dans ta base de connaissances. Si une information n’y figure pas, dis-le clairement sans inventer. Ne complète jamais avec tes connaissances générales. »
Sauvegarde. L’agent est prêt.
Ce que ça fait vraiment
Les tests sur cette configuration (Mini PC Ubuntu, Intel i5, 16 Go de RAM) donnent des résultats concluants sur des documents de quelques pages à une vingtaine de pages. Le modèle cite ses sources, répond aux questions dans le périmètre des documents, et indique clairement quand une information est absente.
Quelques limites à connaître :
Documents texte uniquement. Les modèles testés ici (qwen2.5:3b et les autres) ne traitent pas les images. Envoyer une image depuis Open WebUI produit une erreur. Seul le texte extrait des PDF est utilisable par le RAG.
Les PDF scannés nécessitent une étape supplémentaire. Le moteur d’extraction par défaut d’Open WebUI ne sait pas lire un PDF image (un scan sans couche texte). Si tu essaies d’en déposer un dans une base de connaissances, tu obtiendras une erreur silencieuse ou un document vide. La solution est d’ajouter Tika – un service Apache open source – comme moteur d’extraction. Tika s’installe en container Docker séparé et se connecte à Open WebUI via le réseau Docker. Ce point fait l’objet d’un article à venir dans cette série.
Le system prompt fait la différence. Sans instruction explicite de rester dans les sources, le modèle complète avec ses connaissances générales – les réponses paraissent correctes mais ne s’appuient pas sur tes documents. L’instruction « réponds uniquement à partir des documents fournis » change significativement le comportement.
Les réponses ne sont pas déterministes. Le même modèle, la même question, des sessions différentes peuvent produire des réponses légèrement différentes. C’est une caractéristique fondamentale des LLM, pas un dysfonctionnement – et une bonne raison de tester systématiquement après chaque modification de configuration.
Pour aller plus loin
Cet article fait partie d’une série sur l’IA locale : Créer une IA locale et l’installation de logiciels en containers Docker sous ubuntu : Créer une IA locale
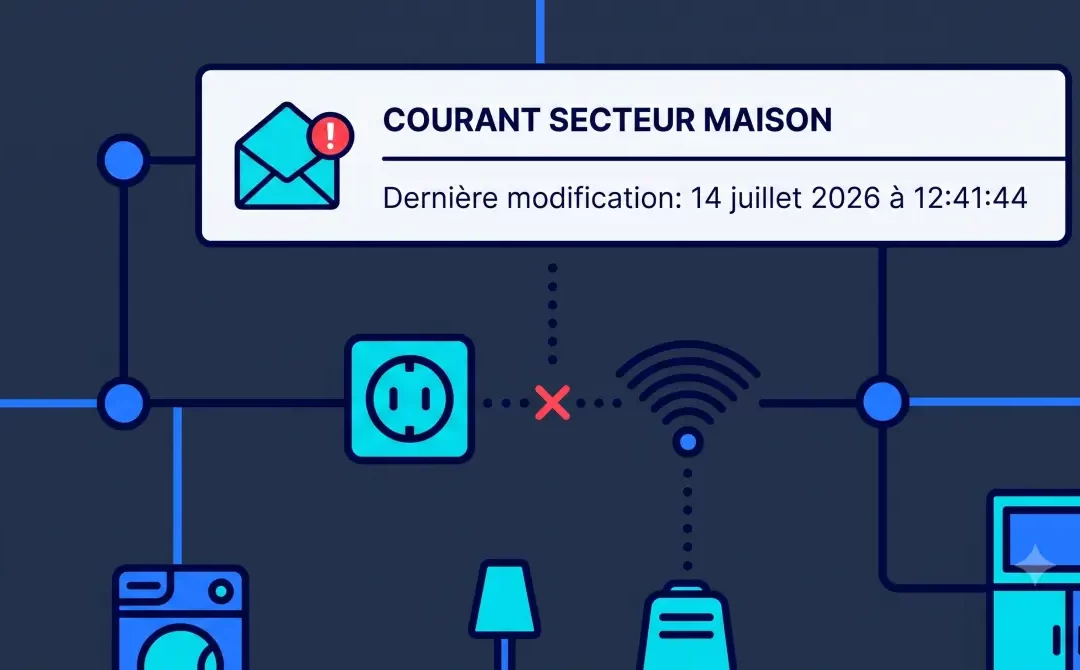
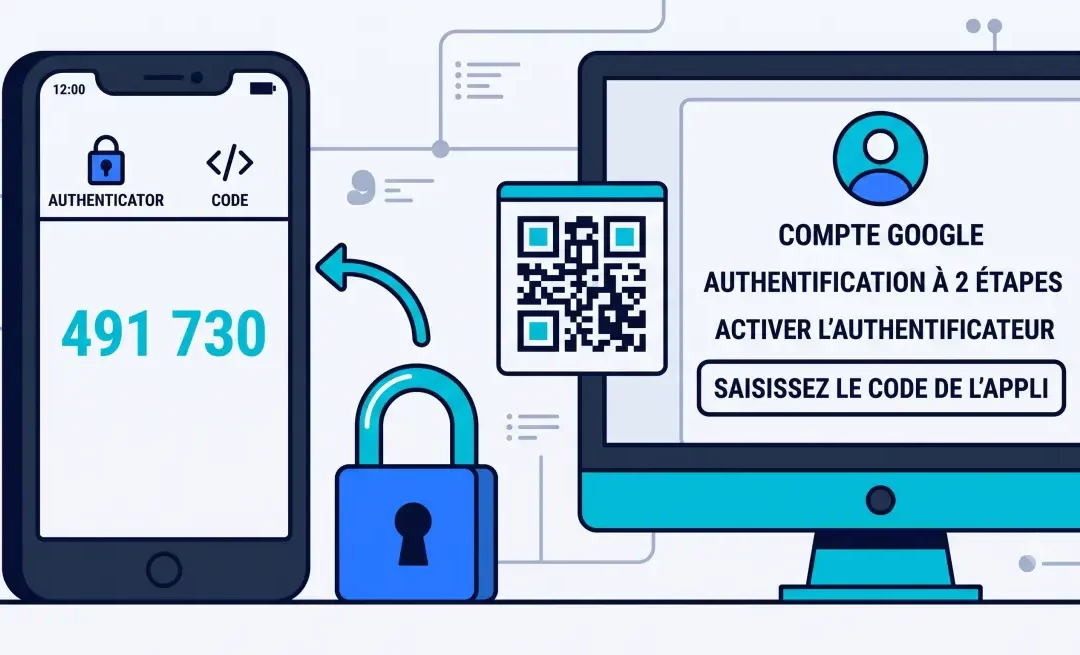
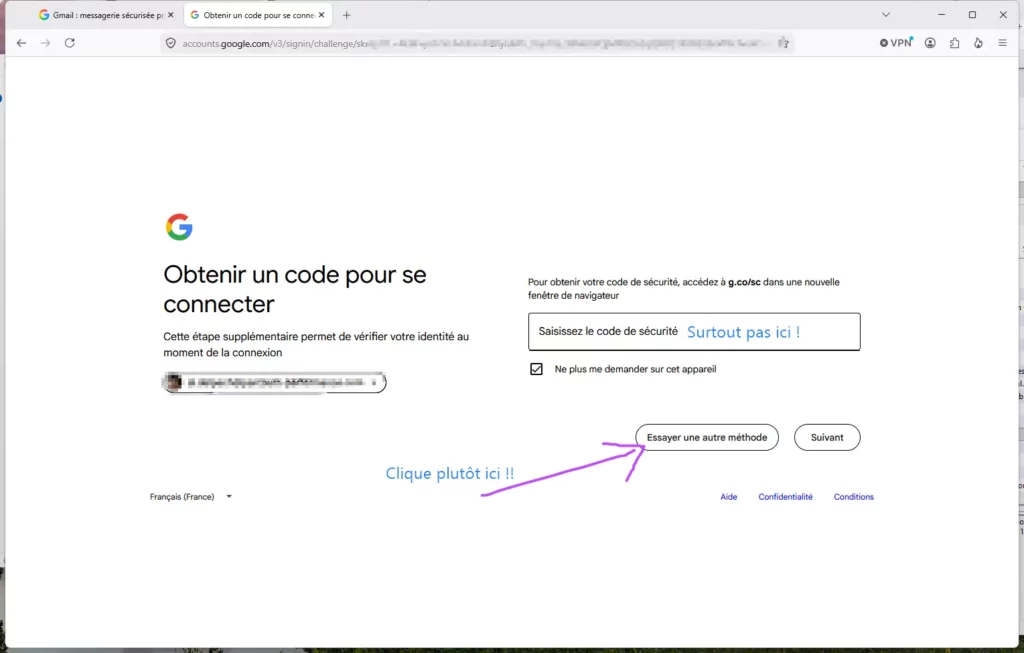
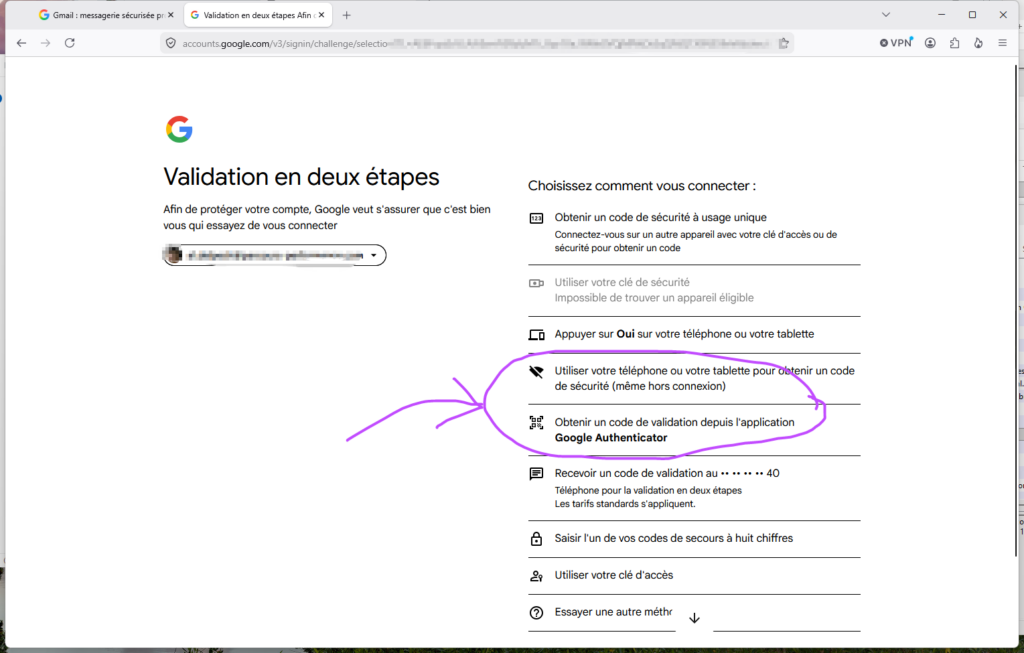
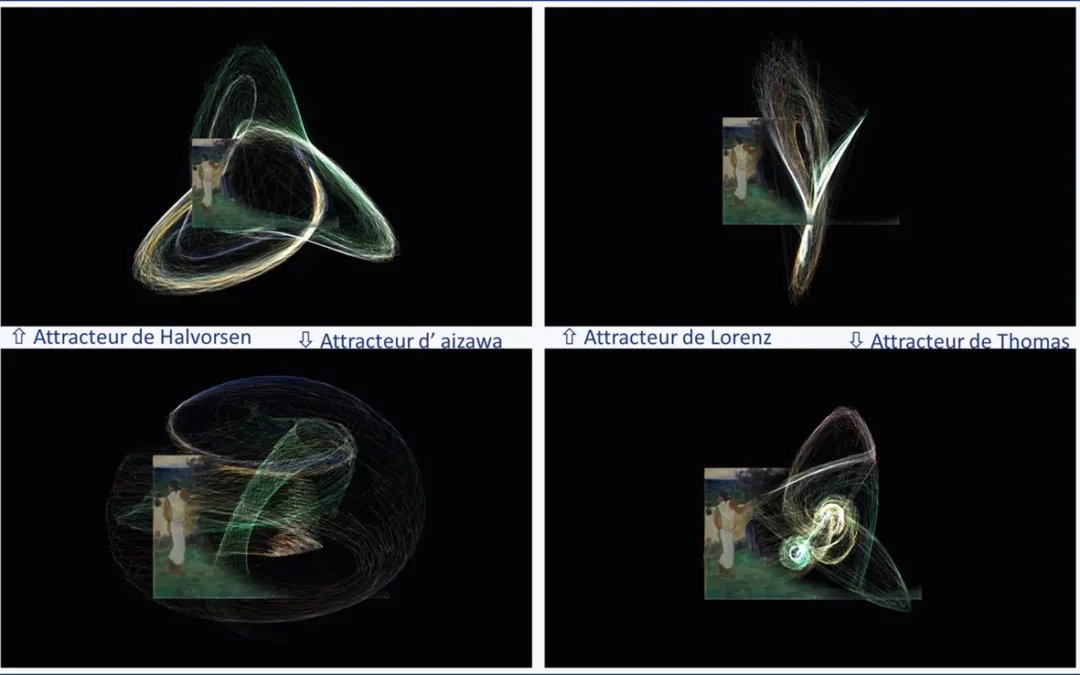

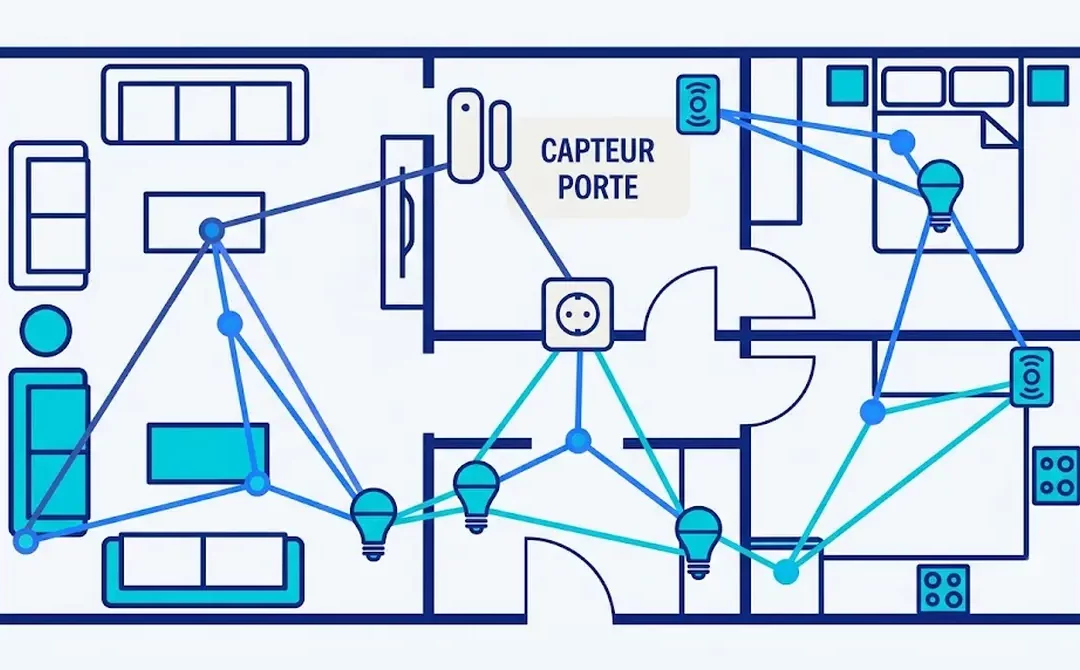
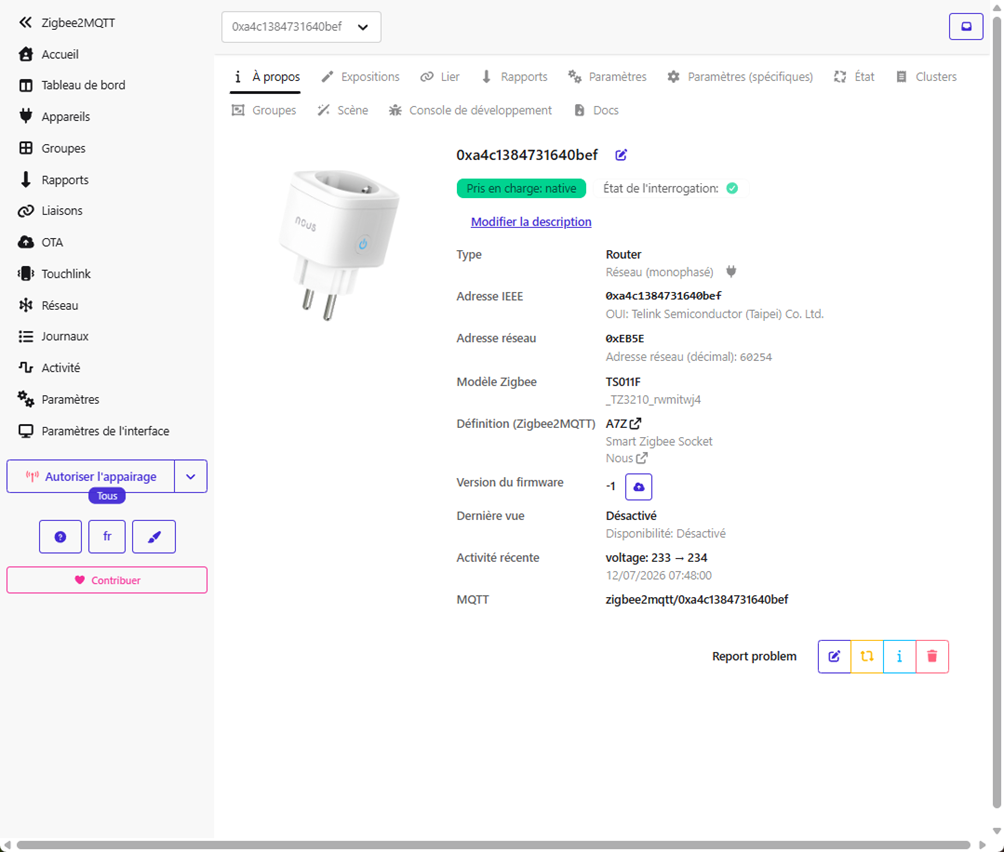
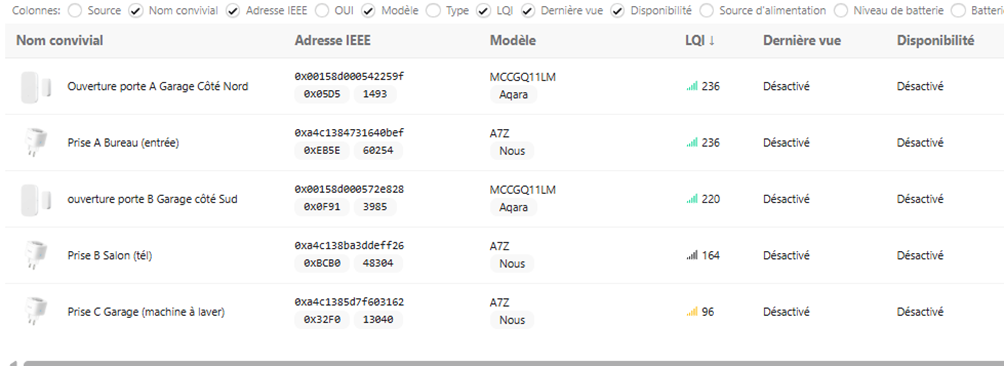
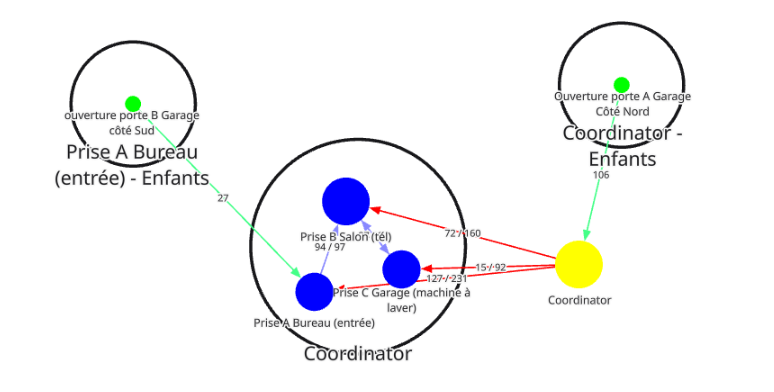


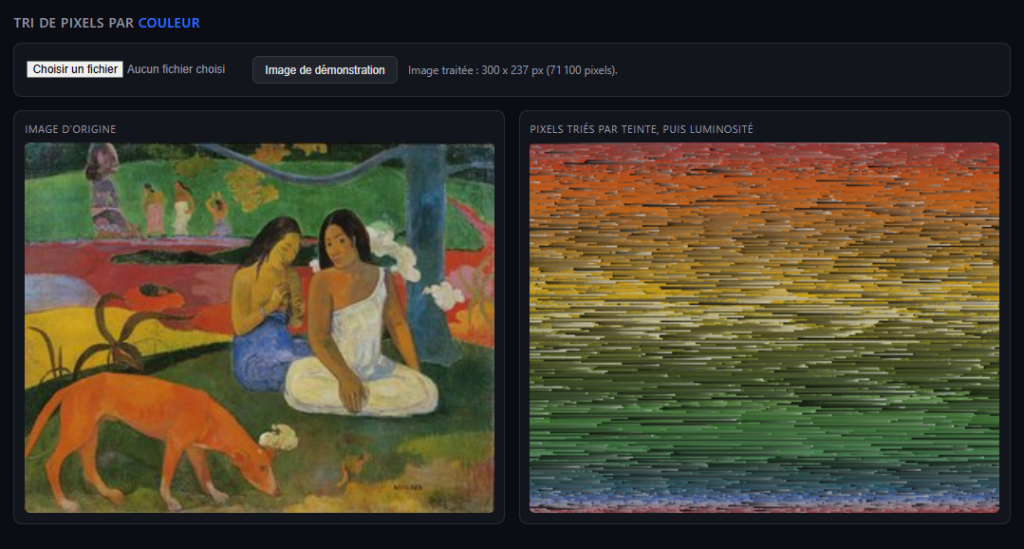
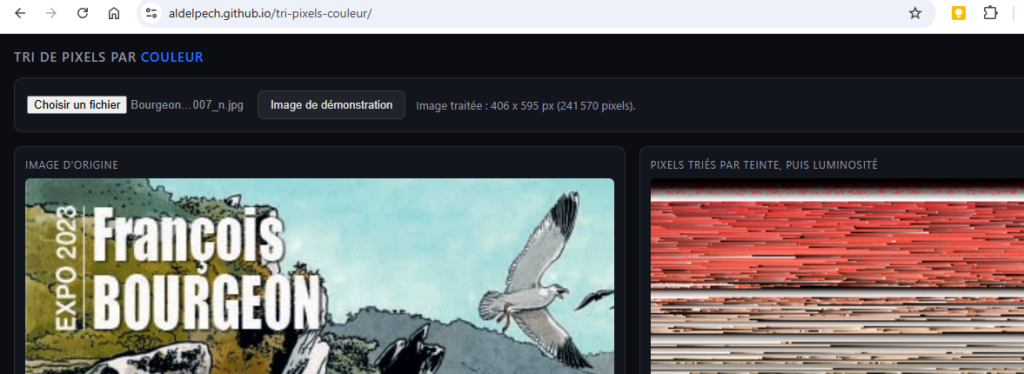
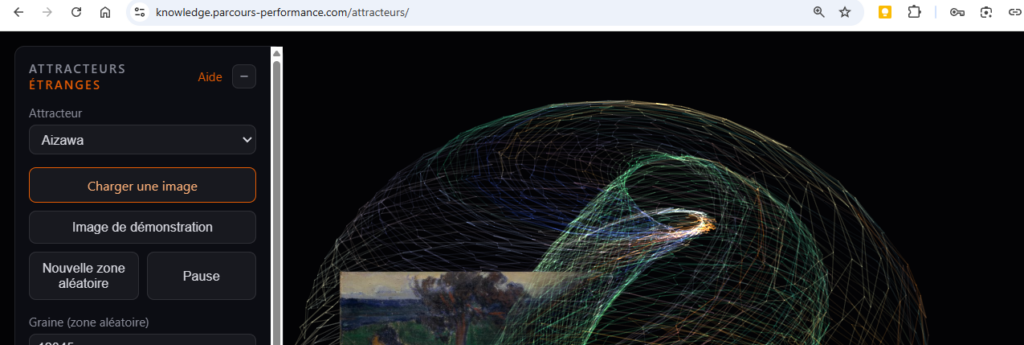
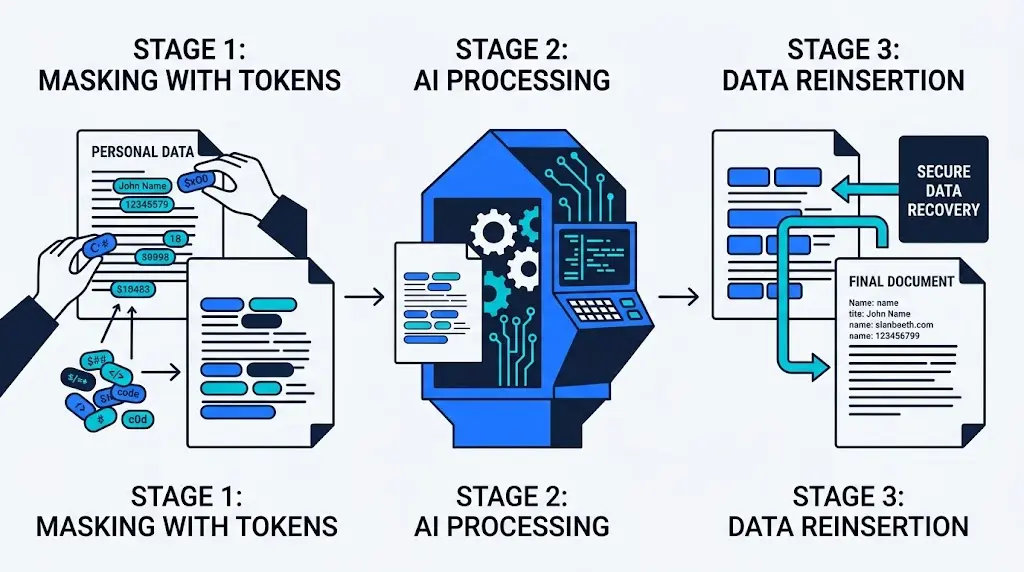
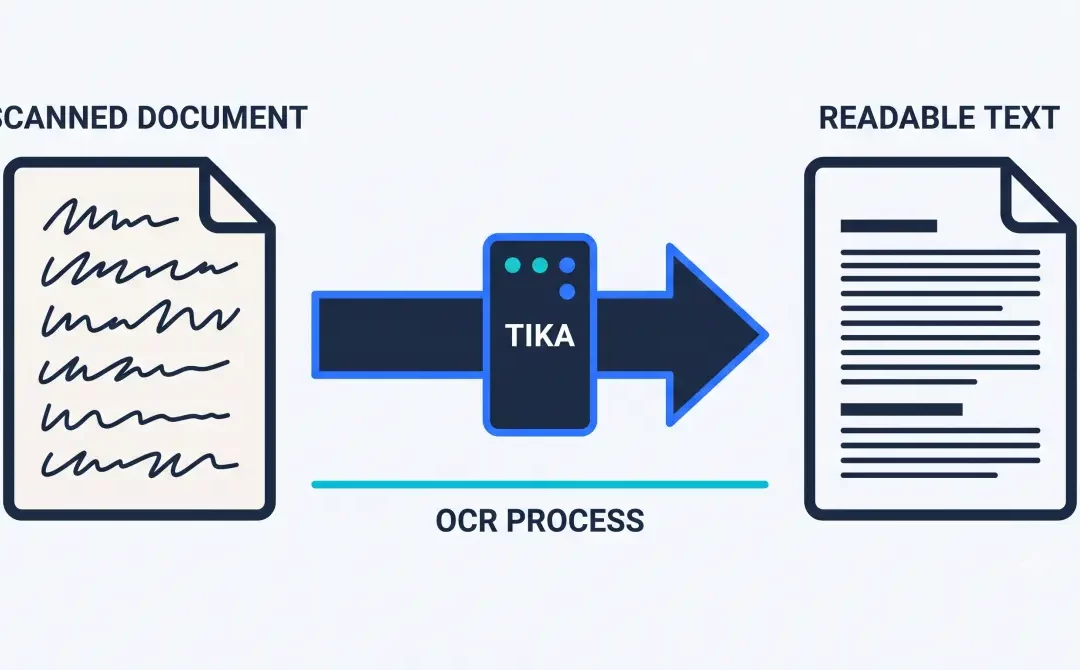
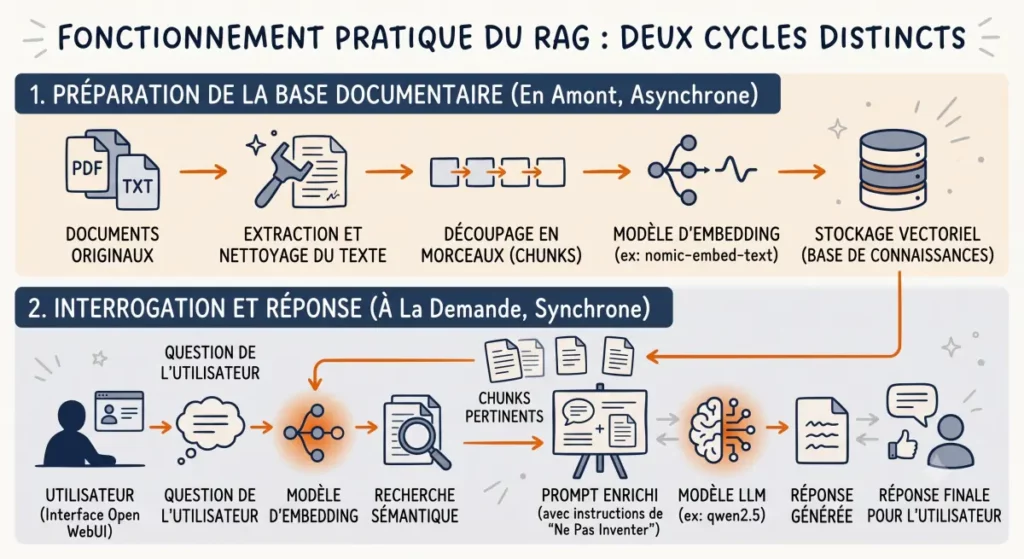
Commentaires récents